
Introduction#
If you want to work with a database, you probably want to get some data into it first. At DoltHub, we’ve spent a good
chunk of time working on our table import feature
which lets you import CSV, JSON, XLSX, and Parquet data into Dolt. In the past couple of months, we’ve added various
improvements to our import path by reducing garbage size and increasing correctness. As our team has experimented with
larger databases and as our users have gotten deeper with our product, we received complaints that imports were getting
slower with very large CSV files (>10m rows). We weren’t sure just how fast users should expect import to be. How much slower
are Dolt’s imports compared to other databases like MySQL? We’ve had success using sysbench
to guide users on query performance. We think a similar benchmark would work well for tracking import performance. In this
blog post, we’ll discuss the benchmarking setup we put together to evaluate Dolt’s performance vis-a-vis MySQL and some
potential performance optimizations.
The Setup#
We considered the following set of independent variables:
- The schema definition
- The number of rows in each file
- The key sort order of each file
We measured the following dependent variables:
- The amount of time the import took to complete
- The Rows per Second imported by the
table importcommand
We decided to generate 6 different CSV files according to the following schema:
CREATE TABLE `test` (
`pk` int NOT NULL,
`c1` bigint DEFAULT NULL,
`c2` char(1) DEFAULT NULL,
`c3` datetime DEFAULT NULL,
`c4` double DEFAULT NULL,
`c5` tinyint DEFAULT NULL,
`c6` float DEFAULT NULL,
`c7` varchar(255) DEFAULT NULL,
`c8` varbinary(255) DEFAULT NULL,
`c9` text DEFAULT NULL,
PRIMARY KEY (`pk`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_bin;- A CSV file with 100k rows in sorted key order
- A CSV file with 100k rows in random key order
- A CSV file with 1m rows in sorted key order
- A CSV file with 1m rows in random key order
- A CSV file with 10m rows in sorted key order
- A CSV file with 10m rows in random key order
These files are loaded into both Dolt and MySQL database instances in a containerized environment running in a Dedicated Kubernetes Node. This process is very similar to what we wrote about in our previous blog about performance-benchmarking.
Results#
Below is a chart comparing MySQL version 8.0.22 to our most recent Dolt version of 0.40.19. We are about 10x slower than MySQL with bulk imports.
| name | program | version | from_time | from_rps | program | version | to_time | to_rps | rps_multiplier |
|-----------------|---------|---------|-----------|----------|---------|---------|---------|---------|----------------|
| 100k-random.csv | dolt | 0.40.19 | 13s | 7528.9 | mysql | 8.0.22 | 1s | 71466.8 | 9.5 |
| 100k-sorted.csv | dolt | 0.40.19 | 13s | 7561.9 | mysql | 8.0.22 | 1s | 74863.4 | 9.9 |
| 1m-random.csv | dolt | 0.40.19 | 2m31s | 6617.3 | mysql | 8.0.22 | 13s | 74216.1 | 11.2 |
| 1m-sorted.csv | dolt | 0.40.19 | 2m30s | 6646.1 | mysql | 8.0.22 | 12s | 81445.6 | 12.3 |
| 10m-random.csv | dolt | 0.40.19 | 27m55s | 5971.5 | mysql | 8.0.22 | 2m16s | 73594.2 | 12.3 |
| 10m-sorted.csv | dolt | 0.40.19 | 28m1s | 5950.1 | mysql | 8.0.22 | 2m15s | 73986.3 | 12.4 |These results were a little surprising to us. When we look at our
sysbench write performance results we
typically found ourselves at around 6x slower than MySQL. Why was MySQL LOAD DATA
so much better than our import path?
I started profiling dolt table import and investigating MySQL’s implementation of LOAD DATA to get a sense of
what was going on. Here’s an example Pprof that I worked with.
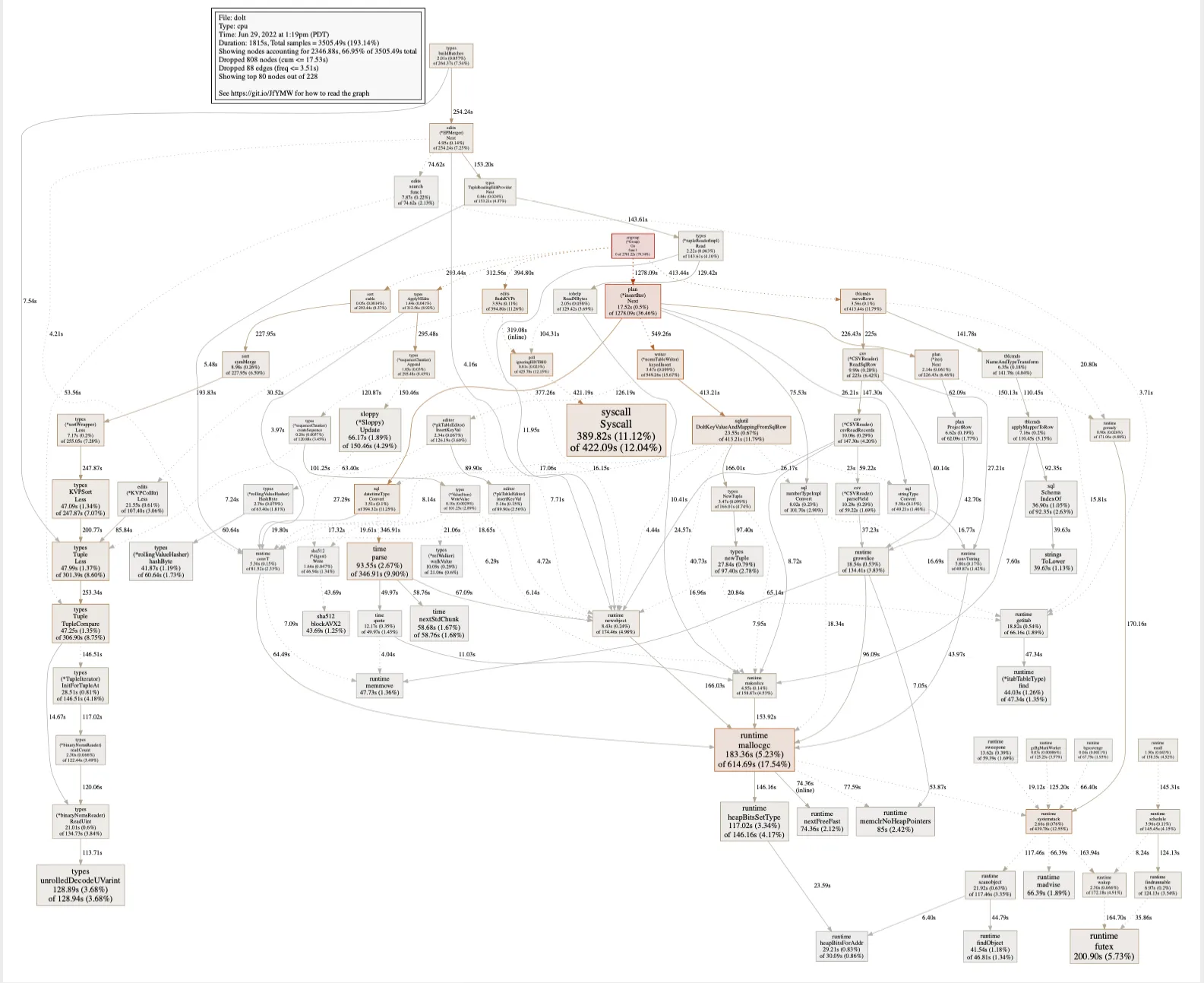
If you’ve studied GoLang performance profiles before you’ll probably notice some pretty big problems in this profile.
- We use two different encodings of a SQL “row”. One is a query engine specific implementation
and the other is storage engine specific.
There is overhead in converting between those two types as indicated by the usage of
DoltKeyValueMappingFromSqlRow - We perform a substantial amount of type conversions. File rows are read in as strings and then converted into both of
our row formats. The import tool itself spent nearly 5 minutes doing
time.Parseto interpret our datetime strings. - Memory allocation is exacerbated by an unoptimized row implementation that also requires a wide amount of type conversions when performing engine operations.
From an implementation perspective, we’re also missing some features that can improve our performance.
-
Chunking the relevant import file and leveraging concurrency when reading and writing it.
-
Allowing for Prolly tree merge operations. Right now our Prolly tree can only be materialized by one thread. If we could concurrently manifest and merge Prolly trees we could have many concurrent threads writing to the storage engine versus the single-threaded import process. MySQL does something similar with B-Trees where they can have multiple threads manifesting different B-Trees that then get merged.
Conclusion#
Dolt is well on its way to becoming a serious 1.0 database that is useful in any engineering organization. As we mature, we are going to spend more resources creating benchmarks ranging from systems tables to our aggregation queries. And of course, we’ll make these benchmarks faster :). If database performance is your thing feel free to hop on our Discord and learn more!