
The software development world vs. the database admin world#
Why is the way we make changes to software so different from the way we make changes to databases? It’s impossible not to notice. In one world we have source control and a whole constellation of tools and workflows like CI/CD surrounding them. And in the other world we have very, very paranoid DBA veterans with war stories that will turn your hair shock white. Why is this the status quo, and can we do better?

In this article, we’re going to examine two different real-world scenarios when you might want to deploy some changes to your application, and consider how different our plan of action is when we talk about code versus databases.
There’s a problem in production#
It’s a normal Wednesday morning. You roll into the office at 10:30 and open your email to see a new bug report: there’s a bug in production. It’s serious, but not that urgent. You need to fix it, but an emergency deployment to roll back to a previous version would be overkill and break other things.
You need to fix the bug. How do you proceed?
- Run
git cloneon your laptop to get a local copy of the code, then rungit checkout -b bugfix v1.5.2to make your local copy match what’s in production. Then you debug it locally. sshonto a production host and begin editing the code withemacs(orvim, this isn’t supposed to be the controversial part of the essay)

If you answered #2, then either you work for Knight Capital… or else we’re not talking about a problem with the code, we’re talking about a problem with the data in a production database. Because that’s how you debug such problems, right? You connect to the database and start poking around.
mysql -h production-db.mycompany.com -uadminI mean, how else would you do it? That’s how we operate databases, always has been. Let’s hope you don’t accidentally
forget a WHERE clause in your DELETE statement.
A customer wants a new feature#
OK, it’s not an emergency anymore. It’s a more typical Wednesday morning. You did your sprint planning last week, and today it’s your task to implement a small new feature. Obviously, you’ll need to write some new code files and edit other existing code files to accomplish this.
You need to build this new feature. How do you proceed?
- Run
git cloneon your laptop to get a local copy of the code, then rungit checkout -b new-featureto create a branch. Then you make your changes. When you’re done, you open a pull request for someone to review. sshonto one of the production hosts, and begin editing the code withvim- Closely examine the code in production, think hard, and then locally write a patch file that when run on that code will produce the code you want. When it’s time to deploy, run that patch in prod.
- You are scared to work with production code, so you work on a separate, parallel code base that mostly works the same instead. When you’re happy with your changes you carefully translate them to the real codebase, maybe using patch files like in #3.

These are leading questions, but I’m making a point here.
Option #1 is how basically everyone who isn’t criminally negligent develops software in a team setting in 2022. (And most of them in a solo setting too)
Option #2 is how a majority of software engineers manage database changes, like creating a new table or altering an existing one, or adding some rows to a domain table. In 2022.
Option #3 describes the process of “schema migration”, which is considered a safer way to make schema changes. It’s a set of patches, with a database counter that knows how many have been applied already.
Option #4 describes the common practice of developing against SQLite or another light-weight, local database for eventual deployment against Postgres or another “real” production database. It mostly works the same, except where it doesn’t. You don’t have any of the data that’s in production. You generally keep two parallel copies of your schema migration scripts in this case.
There has to be a better way#
Today, in 2022, we know better than to edit source files in production directly. You get a copy of the code, make
changes, and merge them back. It’s managed by version control software like git, and supported by a bunch of workflow
tools like CI/CD and processes like code review.
But in the database world, changing production directly is still state of the art. At best, you version control a set of patch files that some tool will apply on your behalf once they hit production. And if you want to test some changes for a feature you’re developing locally, you can either do it against production (risk a catastrophe) or else use a development version (not the real data, often not even the same database software). Everyone who has done database application development knows there are some issues that only manifest with the database and the data in production.
Why do we tolerate workflows with databases that we never would with source code? Most people would never dream of developing software without using version control for their source, but when it comes to the database world, all that goes out the window. It still hasn’t sunk in for most people just how badly databases, as a tool, fit into the modern software development workflow.
What if you had a database that let you use the same source control concepts you’re used to when working with source code?
A database of one’s own (with apologies to Virginia Woolf)#
We wrote such a database, and we’re convinced it’s a better way to write database applications. It’s called Dolt, and it’s the world’s first version-controlled SQL database, a database you can fork and clone, branch and merge, push and pull just like source code in a git repository. It’s the only SQL database with these features, and we built the storage engine from the ground up to make this possible.
![]()
When we tell people about this, there are two typical responses:
- That’s really cool, how come nobody has done this before?
- What would I use that for?
This article is one in a series where we attempt to answer the second question. We’re working against 50 years of inertia, trying to build a set of narratives to get people to think of their database the same way they think of their source code. Last time, we examined the metaphor of branches and demonstrated how you could think of them as very long-running transactions in the database context. Today, we’re going to examine the metaphor of cloning, and demonstrate how you should think of a database clone: as a database of one’s own.

Let’s examine how our two scenarios above play out with a version controlled database like Dolt.
Bug in production, with Dolt#
Rewind to that same fateful Wednesday morning. You check your email and see the bug report. You clone the source code and attempt to debug the problem locally, but you can’t reproduce it. It has something to do with the data in production, but you have no idea what. How do you fix this problem without possibly causing a disaster on the production database? The same way you are planning to fix the source code: you make a clone first.
% dolt clone myCompany/prod
% cd prod
% dolt checkout -b bug-fix
% dolt sql-serverWith the exception of the final command to start a server, this workflow exactly matches how you get a copy of the
source code to edit locally. The commands are even the same, just change git to dolt and you know how to run them.
The end result is that you have an exact copy of the production database, running locally. It’s your own private
database. You can mess it up all you want, it won’t break production.
A customer wants a new feature, with Dolt#
It’s Wednesday morning again, and you’ve chosen your card off the kanban board. Time to write that feature! You clone
the git repository and create a branch. Your next step is, obviously, to do that for the database too.
% dolt clone myCompany/prod
% cd prod
% dolt checkout -b new-feature
% dolt sql-serverIt’s your own private database, with the same data that’s in production. It lives right next to your own private copy of the source code, the same code that’s in production. You have an exact reproduction of your application’s state in prod, but running isolated and locally.
Now let’s get to work. You have to make changes to the source code of course, but first you need to make some schema changes to support the new feature. You have to create a new table and change the definition of an existing one. So you fire up a SQL client of your choice and do that.
mysql> create table birthdays(customerId int, birthday date, send_reminder tinyint not null default 0);
mysql> alter table customers add column has_birthday tinyint not null default 0;Hey did you just add a non-nullable column to that production table? Did you know doing that rewrites every row and will cause all writes to block while it’s running? You didn’t? Not to worry, this is your personal database, there aren’t any other writers.
So you’ve made your changes, you’ve tested them locally, and your PR has been approved. Time to deploy your changes to production.
% dolt commit -am "new schema"
% dolt push origin new-featureIf you want to have your changes reviewed (usually a good idea), open a PR using DoltHub or DoltLab. Your team can examine the diff and make sure your changes make sense.
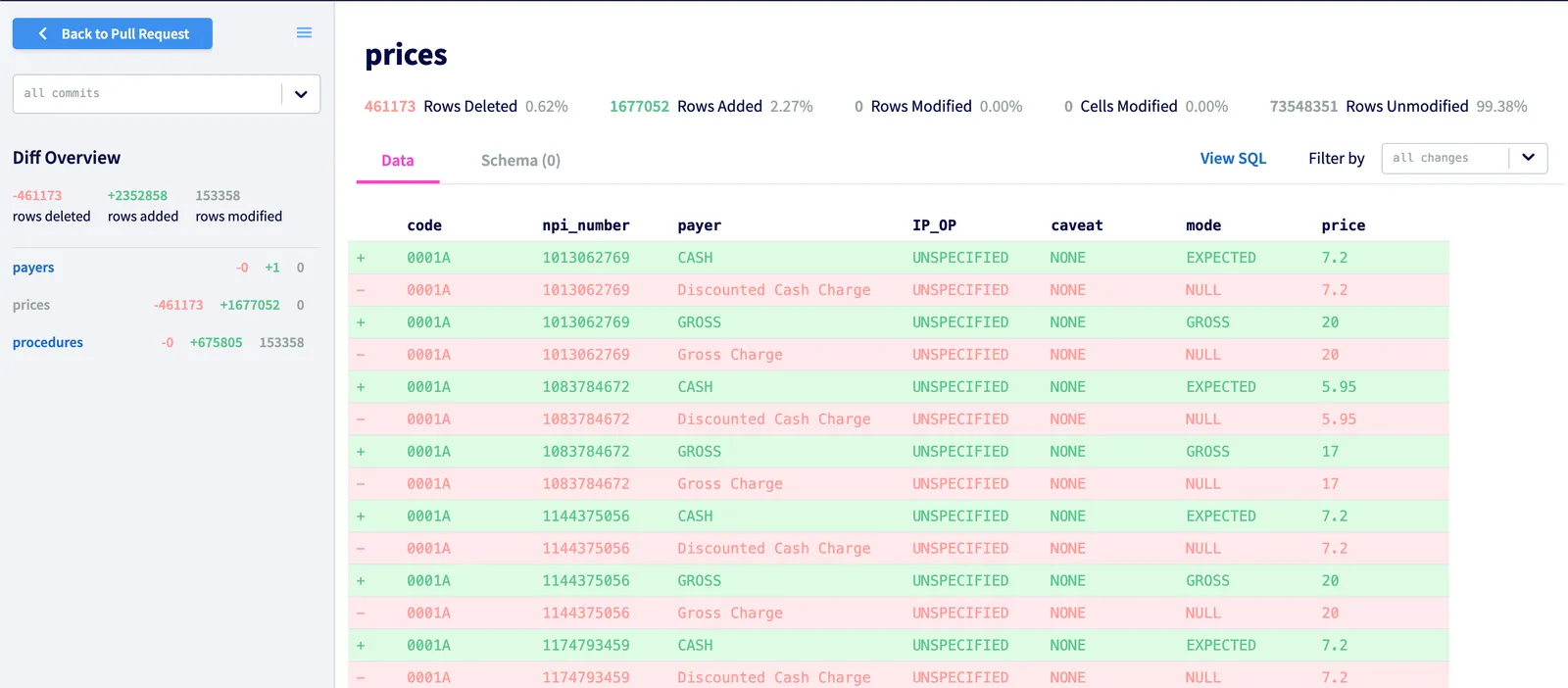
Almost done. The final step is to merge your changes back to the main branch on the production server. This is
analogous to merging your source code changes back to the main branch in the GitHub repo.
% mysql -h production-db.mycompany.com -uadmin
mysql> select dolt_checkout('main'); -- probably unnecessary, but just to be sure we're on main
mysql> select dolt_merge('new-feature');Huh? Didn’t we just claim that modifying a production database like this was dangerous? Don’t panic! If something bad happens, rollback is instantaneous and easy, just like with git. This is another of the useful superpowers of a version controlled database.
mysql> select dolt_reset('--hard', 'HEAD~');Conclusion#
It’s not 1990 anymore. Software development and databases have come a long way. It’s time to re-imagine how database application development should work in the modern software environment and free yourself from obsolete constraints, like having completely different workflows for changing code and data. With Dolt, you can manage your database just like you manage your source code.
Interested? Come chat with us on our Discord. Let’s get you started building your next application on top of a Dolt database.