
We aim to make Dolt 100% MySQL compliant, but we are also committed to making Dolt fast. My colleagues are hard at work adding new optimizations to our storage layer — inlining functions, minimizing memory allocations, dovetailing cache locality, eliminating branch hazards, and bit twiddling. This blog will be a teaser for bigger changes to come. Today we will focus on one simple performance optimization in Dolt’s SQL engine, go-mysql-server (GMS), that detects and removes duplicate filters, boosting the performance of some queries by up to 30%.
TLDR; The most recent Dolt release introduces a change that eliminates filters used for range scan index lookups, speeding up most queries with WHERE clauses over primary key fields.
Background#
A year ago, the SELECT statement below was bottlenecked by tablescans. We moved the whole table off disk before filtering a fraction of rows for output:
SELECT * FROM a WHERE x < 0 or x = 1;
+----------------------------------------------+
| plan |
+----------------------------------------------+
| Indexed table access on indexes [a.x], [a.x] |
| └─ Exchange(parallelism=8) |
| └─ Filter(a.x < 0 OR a.x = 1) |
| └─ Table(a) |
+----------------------------------------------+Daylon recently upgraded range
scans
to avoid reading unnecessary rows. If we have
an index on x, and 90% of the index keys are positive, we can use the ordered
index to only read 10% of the table.
EXPLAIN SELECT * FROM a WHERE x < 0 or x = 1;
+----------------------------------------+
| plan |
+----------------------------------------+
| Filter((a.x < 0) OR (a.x = 1)) |
| └─ Projected table access on [x y z] |
| └─ IndexedTableAccess(a on [a.x]) |
+----------------------------------------+A 10x performance boost is huge. But as with most optimization, uncovering one bottleneck exposed a host of new inefficiencies. What was once fast is now slow, but in a good way!
Duplicate Filters#
Our attention turns now to the root level Filter used for the index lookup:
EXPLAIN SELECT * FROM a WHERE x < 0 or x = 1;
+----------------------------------------+
| plan |
+----------------------------------------+
| Filter((a.x < 0) OR (a.x = 1)) |
| └─ Projected table access on [x y z] |
| └─ IndexedTableAccess(a on [a.x]) |
+----------------------------------------+Every row returned by IndexedTableAccess already satisfies (x < 0 OR x = 1). The index lookup reads less data from disk and satisfies the
filter in the process. So we want to eliminate
the deadweight outer filter:
EXPLAIN SELECT * from a WHERE x < 0 or x = 1;
+------------------------------------+
| plan |
+------------------------------------+
| Projected table access on [x y z] |
| └─ IndexedTableAccess(a on [a.x]) |
+------------------------------------+The second plan pipelines rows straight from disk to the client, sidestepping any intermediate computational bottlenecks.
To implement this change, we extended our pushdown rule to include
IndexedTableAccess filters, and let a helper function take care of
the heavy lifting:
// subtractExprSet returns all expressions in the first parameter that aren't present in the second.
func subtractExprSet(filters, toSubtract []sql.Expression) []sql.Expression {
var remainder []sql.Expression
for _, e := range filters {
var found bool
for _, s := range toSubtract {
if reflect.DeepEqual(e, s) {
found = true
break
}
}
if !found {
remainder = append(remainder, e)
}
}
return remainder
}In our example query, we subtract the IndexedTableAccess
lookup expressions from the Filter node’s expressions.
When the expressions overlap, remainder is empty, and we
remove the filter entirely.
Results#
Preliminary results look promising!
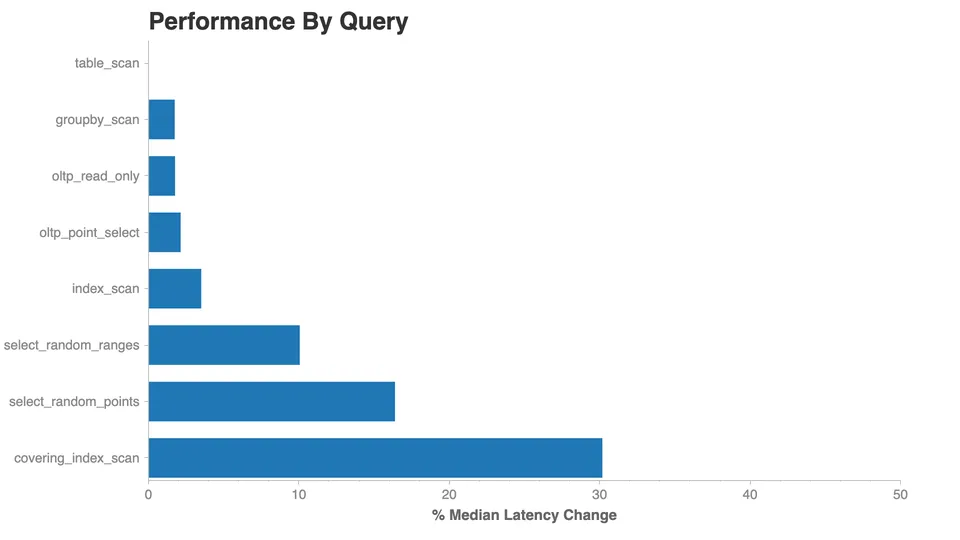
We managed to shave about 16% off of point lookups (x=0), 10% off small
ranges (x BETWEEN 0 and 5), and a whopping 30% off of covering index
scans (like our initial x<0 query). The only queries not impacted by the
change are table scans, which lack filters and intentionally read every row from disk.
The covering_index_scan result was the most surprising for us. Presumably the engine
should take a similar amount of time to fetch a row and execute a filter
whether it was performed on one or many rows. The 30% difference for
covering index scan suggests that there might be another performance
bottleneck we unintentionally sidestepped by removing a filter.
Deeper Dive#
As with range scans, indexes and filters can be incompatible.
For example, an index on x does not help us eliminate a y > 0 filter:
EXPLAIN SELECT * FROM a WHERE y > 0;
+---------------------------------------+
| plan |
+---------------------------------------+
| Filter(a.y > 0) |
| └─ Projected table access on [x y z] |
| └─ Exchange(parallelism=12) |
| └─ Table(a) |
+---------------------------------------+Second, we can push partial filters into scans. A filter like
x < 0 AND y > 0 can push x < 0 into the filter, but y > 0
is left behind to check rows returned by the index lookup:
EXPLAIN SELECT * FROM a WHERE x < 0 AND y > 0;
+----------------------------------------+
| plan |
+----------------------------------------+
| Filter(a.y > 0) |
| └─ Projected table access on [x y z] |
| └─ IndexedTableAccess(a on [a.x]) |
+----------------------------------------+Splitting filters and opportunistically range scanning gives us a double win — less data from disk, and fewer function calls in the execution runtime. Partial wins still matter even if we cannot remove an entire filter.
Future Work#
Inversions (NOT) and IN filters currently elude reflects.DeepEqual
detection because other optimizer rules rearrange their expressions. We would like those
filters to be eliminated like other filters. It would also be nice
if EXPLAIN told us which filters are absorbed by IndexTableAccess
rather than leaving us to guess.
I will spend the meantime combing the optimizer and execution logic for new bottlenecks and performance gains. And as we narrow the gap between Dolt and MySQL on our current set of sysbench tests, we hope to revamp our benchmarks to sharpen our focus to deliver more wins for OLTP use-cases.
Summary#
We piggy-backed off of index improvements to eliminate filter expressions duplicated by range lookups. We saw 10%-30% speedup for queries that 1) have indexes, and 2) use index keys in a WHERE clause.
If you have any questions about Dolt, databases, or Golang performance reach out to us on Twitter, Discord, and GitHub if you have any questions!