
Dolt is an open-source version-controlled
database. It lets you push and pull databases just like you can push and pull
source code with git. You can make changes on a local clone, commit, and then
dolt push them to a remote with a single CLI command. Or if a remote has
upstream changes, you can use dolt pull to download them.
DoltHub is the default remote for Dolt where you can
view Dolt databases online and share them with others. As our customers grow,
we’ll need DoltHub to support pushing, pulling, and viewing many large databases
at once. Last week, we completed the first step in that journey. We pushed all
1TB of the
FBI NIBRS database
to DoltHub. In this article, we’ll discuss not only the immediate memory issues
we had to resolve to do this, but also some of the more difficult infrastructure
challenges that still remain. To understand these problems, we’ll need to deep
dive into the Dolt storage layer, so strap in and put your thinking hats on!
FBI National Incident-Based Reporting System (NIBRS)#
To understand some context, let’s talk about the FBI NIBRS database. The NIBRS database was first imported by Dustin back in 2020 and was originally only 242GBs large. He then updated the database with even more data in 2021. Due to the database’s heavy use of foreign keys, that brought the size to 1TB. We were never able to push the full Dolt database until last week. NIBRS has continuously been an interesting Dolt database for the team because its sheer size pushes Dolt’s and DoltHub’s boundaries. Pushing its full 1TB size is a big win for DoltHub and we’re excited to continue scaling up our infrastructure to allow for even larger databases in the future. So let’s start reviewing the problems we encountered pushing the FBI NIBRS database and deep dive into the Dolt storage layer.
The Dolt storage layer is core to all of Dolt’s and DoltHub’s processes. The
storage layer’s interface is simple. You can ask it whether some data exists,
ask it to fetch that data, or to persist some new data. doltremoteapi is a
service that wraps the storage layer’s interface. It allows the DoltHub website
and Dolt clients to interact with Dolt databases that are stored in AWS S3. When
you view a page on DoltHub, the DoltHub api asks doltremoteapi for it’s storage
layer interface, and uses that interface to query Dolt data. The Dolt CLI also
uses doltremoteapi to push and pull data to DoltHub.
When we initially tried to push NIBRS, doltremoteapi would crash with an out of
memory exception. Early on in the investigation, we knew that this problem was
at the storage layer. To understand what the problem is, let’s talk a little
about chunks.
Chunks and table files#
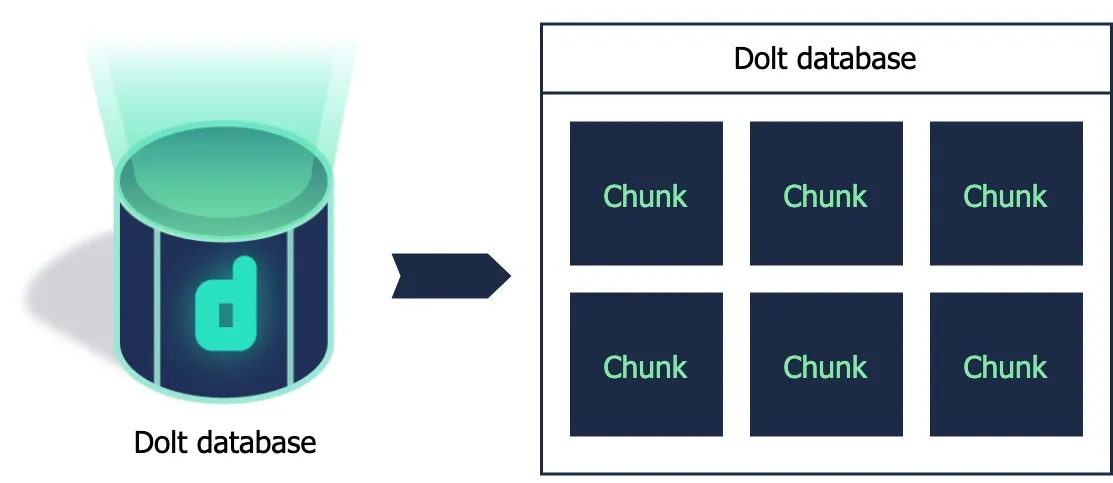
When I talk about the Dolt storage layer interacting with data, what I actually mean is that it interacts with chunks. A chunk is just a group of bytes and its size can be variable. A chunk also has a content based identity called a hash.
The process for encoding Dolt data into chunks is complicated. If you’re interested to understand that process you can read Aaron’s blogs below in the additional reading section and walk through Dolt’s go/store/types package. For today, we’ll skip over that process to focus on the storage layer. All you need to know for this blog is that the data of a Dolt database is stored as chunks, and that the set of all chunks encodes the value(s) of the entire Dolt database.
All of the storage layer’s interfaces deal with chunks. To ask the storage layer if some data exists, you actually ask it whether a chunk exists for a particular chunk hash. To fetch data, you pass a chunk hash to the storage layer, and the storage layers give you back the chunk with that hash. And to persist data, you give the storage layer a chunk to persist.
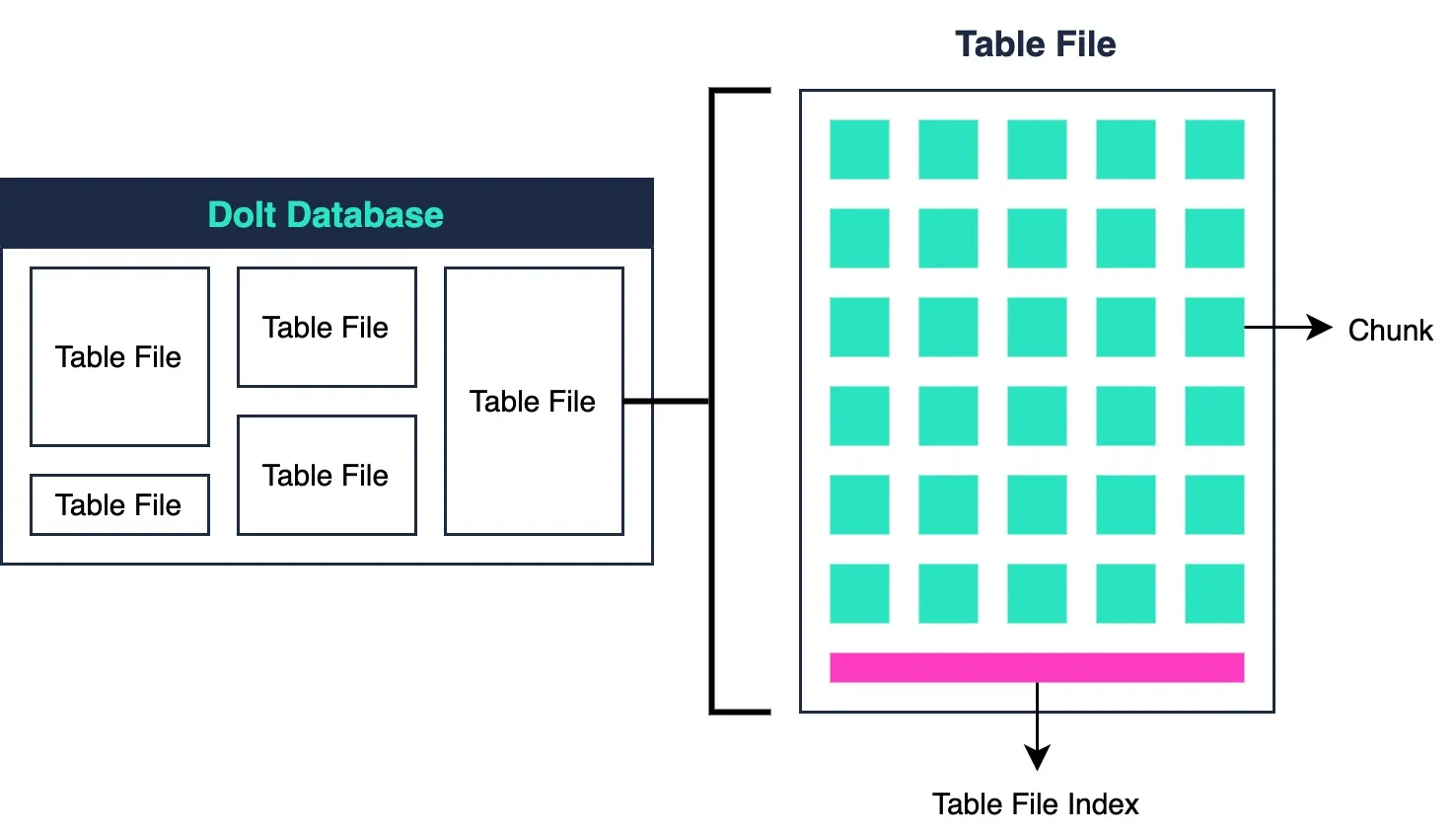
The current storage layer implementation maintains these chunks in what are
called table files. Each table file can hold an arbitrary number of chunks and
all the table files of a Dolt database comprise the entire Dolt database’s data.
If you check the .dolt/noms folder of a dolt database you can see all of these
table files for yourself. Dolt databases can reference an unlimited number of
table files, so to find a chunk, the storage layer has to check each of the
table files.
To quickly check if a certain table file has a chunk with a given hash, the
storage layer maintains a table file index in memory. The table file index
maintains a copy of all the chunk hashes stored in a format that can be
binary searched.
It can quickly tell us if a chunk with hash h exists. Without it, we’d need to
scan each table file in its entirety, which is just not credible at all.
These table file indexes are what cause doltremoteapi to use so much memory and
its consequent crashes. In order for the storage layer to interact with a Dolt
database, it needs to load the table file index for each table file in memory.
Table file indexes in total take up about 1% of the size of a Dolt database, so
for a 1TB database doltremoteapi needs 10GB of memory! This is excessive and if
doltremoteapi needs to support multiple large databases we need to re-implement
this. Previously, we were only giving doltremoteapi 8GBs, so an obvious course
of action was to increase its RAM. So we tried that to no avail. Even giving it
an excess of 25GBs, we were still seeing crashes. We could see the memory usage
grow when we tried to push, hit the 25GB limit, and see the out-of-memory error.
As a new member to the team, it took a quite a while to learn enough about the
table file indexes to understand why. Let’s dig a little deeper, shall we?
The table file index#
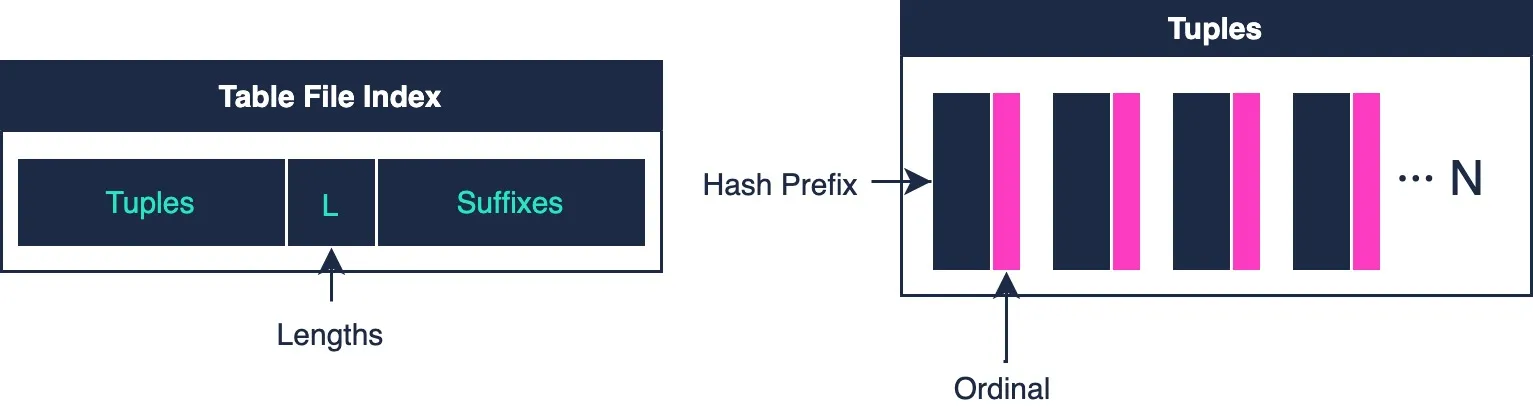
The table file indexes have a unique structure to answer the “do you have this chunk? And where is that chunk?” questions quickly. The index encodes the chunk hash, the chunk’s length, and its offset at the end of the table file. The 20 byte chunk hash is split into an 8 byte prefix and 12 byte suffix which are stored separately. The prefixes are stored in a sorted order, while the lengths and suffixes are stored in the same order as the chunks are in the table file. In order to match a prefix to its corresponding length/suffix, a locator called an ordinal is stored alongside the prefix. We call this prefix-ordinal pair a tuple.
Here’s how to use this index to simultaneously check if a chunk exists and to
find its position in a table file for a given hash h:
- Split the hash
hinto prefixpand suffixs - Binary search the prefixes (tuples) for prefix
p - Once you find the right tuple, we need to check if the corresponding ordinal
is correct. There can be many prefixes that match
h, so we need to also check the suffixes. The ordinal points us to the first suffix we should check. - If the suffix matches, then we know that the chunk exists! Otherwise, keep moving forward in the suffixes until we find a match.
- Finally, If the i-th suffix matched, then we know that the i-th length is the correct one.
- So far we know that the chunk exists and what its length is, but what about its offset? For now, assume that we’ve pre-computed the offsets from the lengths and stored it separately. We can compute offsets by just summing the lengths and recording the current sum for each array index. We use the i-th offset as well.
- Done!
Now that we know what the structure of the index is like, we can talk about how we load the index into memory from a table file and the corresponding problems.
Reducing peak memory usage#
Loading the index into memory was using 4x the required peak memory at first.
The first doubling was caused by a usage of
mmap. Mmap is an OS syscall
that allows you to map an OS file to a region of virtual memory and access that
file just like you access any other memory region. In Go, that means you can
have a byte slice that holds file contents without using an io.Reader to read
the file. You can read and write to that slice and the OS will redirect those
reads and writes to the file. Our initial usage of mmap while good intentioned,
was unnecessary. We first loaded the entire index from the table file into a
byte slice, then used mmap for a region of memory of the same size. This doubled
our peak memory requirements. We decided to eliminate our usage of mmap and just
store the index in the
heap.
// Parse bytes into ti which is a parsed on-heap index
// Create the mmap'd memory region
arr, err := mmap.MapRegion(f, mmapOffheapSize(int(ti.chunkCount)), mmap.RDWR, flags, 0)
if err != nil {
return mmapTableIndex{}, err
}
var a addr
for i := uint32(0); i < ti.chunkCount; i++ {
idx := i * mmapIndexEntrySize
si := addrSuffixSize * ti.ordinalAt(i)
// Copy a parsed index into it
copy(arr[idx:], ti.suffixB[si:si+addrSuffixSize])
e, err := ti.IndexEntry(i, &a)
if err != nil {
return mmapTableIndex{}, err
}
binary.BigEndian.PutUint64(arr[idx+mmapIndexEntryOffsetStart:], e.Offset())
binary.BigEndian.PutUint32(arr[idx+mmapIndexEntryLengthStart:], e.Length())
}
// Throw away parsed index, mmap'd index remainsA snippet showing how we mmap'd a memory region and copied an existing parsed index into it. Source
Parsing the raw bytes into slices of integer primitives caused the second doubling of memory. In the initial version, we first loaded the raw bytes of the index into a byte slice, then parsed that byte slice into integer slices. Since we held both the initial array and our new byte slices as we parsed, that caused the doubling. We knew we could fix this by operating on the raw byte slice directly, but what about the offsets? We previously calculated them as we parsed the raw slice, so what should we do?
Turns out, storing the lengths in the index was a poor decision and storing the
offsets is better. While the lengths do encode the offsets, you have to do
O(n) work to compute them. If you instead store the offsets, you can compute
the lengths in O(1). To compute the lengths you subtract two adjacent offsets.
For example, if the lengths were 1, 10, 3, 4, 9 you can store 1, 11, 14, 18, 27
as your offsets. (We always know that the first chunk is at offset 0.) Then
if you need the 3rd chunk’s length, you subtract the 3rd offset from the 2nd
offset, 14 - 11 is 3.
Converting a stream of lengths into a stream of offsets can also be done in
constant space, but it’s a little tricky. The lengths are uint32’s (4 bytes)
long, while the offsets are uint64’s (8 bytes) long, so you can’t just
convert them in place as you read the lengths. As a solution,
we wrote an idiomatic Go io.Reader
to convert the lengths. It only uses the buffer p provided by Read as its
computation space.
From go/store/nbs/index_transformer.go:
func (tra *OffsetsReader) Read(p []byte) (n int, err error) {
// p is the byte slice that we are reading into.
//
// Read as many lengths from our source reader, as offsets we can fit into p.
// Which is half.
//
// Strategy is to first read lengths into the second half of p.
// Then, while iterating the lengths at the end of p, compute the current offset,
// and write it to the beginning of p.
// Align p
rem := len(p) % offsetSize
p = p[:len(p)-rem]
// Read lengths into second half of p
secondHalf := p[len(p)/2:]
n, err = tra.lengthsReader.Read(secondHalf)
if err != nil {
return 0, err
}
if n%lengthSize != 0 {
return 0, ErrNotEnoughBytes
}
// Iterate lengths in second half of p while writing offsets starting from the beginning.
// On the last iteration, we overwrite the last length with the final offset.
for l, r := 0, 0; r < n; l, r = l+offsetSize, r+lengthSize {
lengthBytes := secondHalf[r : r+lengthSize]
length := binary.BigEndian.Uint32(lengthBytes)
tra.offset += uint64(length)
offsetBytes := p[l : l+offsetSize]
binary.BigEndian.PutUint64(offsetBytes, tra.offset)
}
return n * 2, nil
}Other considerations#
With the above fixes and minor optimizations we were finally able to push NIBRS
without doltremoteapi crashing, but there’s still plenty of work to do. For
example, we won’t be able to handle more than 1 or 2 large 1TB databases at a
time without running out of memory. Potential solutions include re-implementing
our storage engine to access index information that has been externalized in
some manner. An idea was to keep index information on AWS DynamoDB
and use queries to answer our “has chunk?” question. Another idea was to keep
the index on disk.
By using a guess strategy, keeping the indexes on disk might be credible from a performance standpoint. Random disk reads are orders of magnitudes slower than memory reads so we can’t use a binary search to find a particular prefix. We need to take advantage of the fact that sequential disk reads can be faster than random memory accesses.

Because our hash is uniformly distributed, we can guess where a particular prefix might be in the array just from its value. Once we make a guess, we compare the prefix to the value at the guess location. If the value is less than the prefix, we scan to the right, otherwise we scan to the left.
We can additionally increase performance of our disk index by using a Bloom filter that can optimistically reduce the number of “has chunk?” queries the index needs to answer. A Bloom filter can quickly tell us if a particular chunk hash is in our index. It reports false positives, but any negative has absolute certainty. For any positive, we simply use the index as normal to check if it’s a false positive.
Conclusion#
Implementing the disk index or externalizing our index information to DynamoDB is easier said than done. We need to first validate and benchmark our ideas and then implement them in a way that works for the end user. Some pending questions are:
- Should we and how do we evict indexes at the storage layer when
doltremoteapi’s memory is full? - What are the “has chunk?” performance characteristics of using DynamoDB vs a disk index?
- If we use components that need to be prepared like DynamoDB or Bloom filters, when do we prepare them? And how do we ensure that they are up to date with any potential writes?
- What are the associated costs with using an externalized service like DynamoDB?
We’ll continue to improve the memory utilization of the Dolt storage layer and push to make those improvements visible to our DoltHub users. If you’re interested in hearing more about the changes we plan to make, or even want to help us do it, come talk to us on Discord. We’re excited to meet you!
Next time, we’ll talk more about the mechanics of dolt push and dolt pull
and how the performance characteristics of the table file indexes affect them.
We’ll continue on from Aaron’s article
here about
pushing and pulling on Merkle DAGs.
Additional reading#
Aaron’s technical blogs on how Dolt stores table data, how that data is structurally shared, prolly trees and efficient diff: