
Introduction#
Back in November, we announced support for uploading CSV files on DoltHub directly to Dolt repository commits. Since then, we’ve been quickly iterating on features for upload on the web. We recently released changes to our implementation which allow users to upload much larger files than they could previously—files up to 128MB in size. This blog post explores the changes we had to make in order to support larger file uploads and offers a small exploration of our approach to incremental product delivery.
Overview#
Upload on the web was introduced back in November with support for uploading and importing CSVs directly to a Dolt repository. The original announcement post does a great job of introducing the functionality. At the time, we knew that the implementation was just the first step along the path to full featured import and editing features on DoltHub, and we had plans to iterate on it quickly. One of the first improvements we wanted to make was to support importing larger files.
When we first built import on the web, we went for the simplest implementation that would deliver our users value. This meant that we included the import payload directly in the RPCs that were generating the import preview and the imported Dolt commits after the import was processed. This was a great way to land the feature quickly and iterate on the user experience, but it had limitations.
Our API server enforces limits on request payload size and acceptable request timeouts and we like the operational characteristics of keeping those things pretty homogenous across different RPCs. We could have increased these arbitrary limits, up to at least a point, but we knew there were limits to how far we would want to push a design like that. So after landing the initial support for import on the web, we started implementing a way to communicate the import payload and to perform the import work out-of-band of API RPCs themselves.
Moving the payload out of band#
Our API server is a gRPC service that communicates in request and response payloads encoded as protobuf messages. We knew that we didn’t want exceptionally large request payloads inbound to the API server itself, and so our first step in supporting large file uploads was to move the import content itself out of band.
We implemented an RPC on the API server that a client could use in order to get a description of an upload location. The website can then upload the contents of the import file to that location. Once the import contents have been uploaded to this location, the client can come back with a file import RPC that has all the information it did previously, but instead of including the file contents inline it now includes a reference to the uploaded content.
The flow ends up looking like:
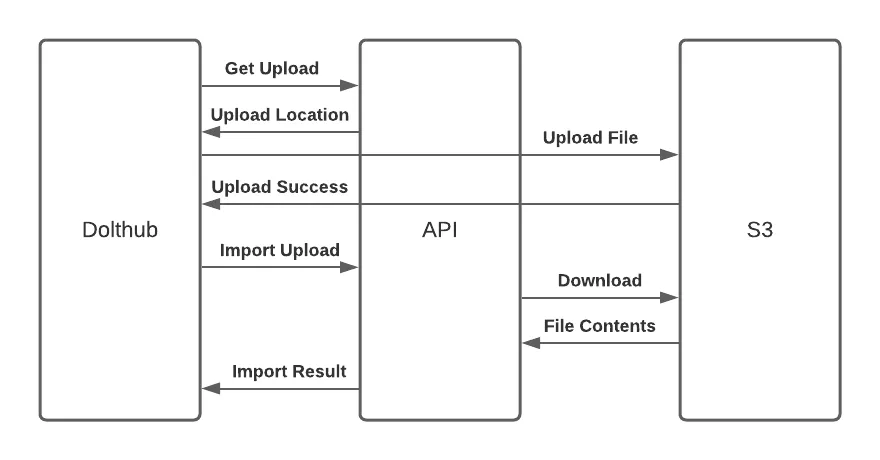
This is more complicated state management on the client, but it provides some real benefits:
-
The client can coordinate with the API to interact with the same import file contents multiple times without the client needing to upload the contents more than once and with the API staying stateless. That means the client can let the user iterate on the schema of the imported data, preview the import diffs, and finally import the content to create a commit in their DoltHub repository, all while the client only uploads the CSV file once.
-
The client and the API can leverage S3 features as an HTTP server and a featureful blob storage API to reduce implementation complexity elsewhere. For example, both client and server can make good use of Transfer-Encoding to get transit compression without having to build that into our API semantics. We can also use things like the S3 object expire time, since these are all short term assets that are only needed for the import flow, to transparently delete the content after it is no longer necessary.
After moving the import contents payload out of band, we were no longer constrained by our API server’s maximum request payload limit when it came to choosing a max file upload to support. But we quickly hit another limit when we tried to increase our maximum import file size. The RPCs to preview the import and create the import commit itself were still synchronous. Similar to request size limits, we have standard timeouts on how long synchronous RPC requests can run. Our next step was to move the import processing out-of-band so that it could proceed decoupled from the lifecycle of an API RPC.
Moving the processing out of band#
We decided to move the import operation from an RPC that provided
import results synchronously to an RPC that spawned a long-running
operation that could be polled for completion by the client. Existing
API patterns in the gRPC ecosystem provided a lot of guidance here,
and we adopted an adaptation of the Operation model from the
googleapis
repository.
That model looks like this1:
// This resource represents a long-running operation that is the result of a
// network API call.
message Operation {
// The server-assigned name, which is only unique within the same service that
// originally returns it. If you use the default HTTP mapping, the
// `name` should be a resource name ending with `operations/{unique_id}`.
string name = 1;
// Service-specific metadata associated with the operation. It typically
// contains progress information and common metadata such as create time.
// Some services might not provide such metadata. Any method that returns a
// long-running operation should document the metadata type, if any.
google.protobuf.Any metadata = 2;
// If the value is `false`, it means the operation is still in progress.
// If `true`, the operation is completed, and either `error` or `response` is
// available.
bool done = 3;
// The operation result, which can be either an `error` or a valid `response`.
// If `done` == `false`, neither `error` nor `response` is set.
// If `done` == `true`, exactly one of `error` or `response` is set.
oneof result {
// The error result of the operation in case of failure or cancellation.
google.rpc.Status error = 4;
// The normal response of the operation in case of success. If the original
// method returns no data on success, such as `Delete`, the response is
// `google.protobuf.Empty`. If the original method is standard
// `Get`/`Create`/`Update`, the response should be the resource. For other
// methods, the response should have the type `XxxResponse`, where `Xxx`
// is the original method name. For example, if the original method name
// is `TakeSnapshot()`, the inferred response type is
// `TakeSnapshotResponse`.
google.protobuf.Any response = 5;
}
}By building against this interface, we can provide a common model for backend implementations and client interactions for any RPCs in the future that need to do things that might take more time than would be appropriate for a synchronous RPC.
In the continued spirit of incrementality, we went for a simple background operation implementation on our backend. When we need to start some background work, such as the work to generate a file import preview, we:
-
Commit a database record to our database which will be associated with the operation we are creating. This record has an ID, a creating user, a timeout deadline timestamp and the creating request payload. It has null fields where a result payload or an error status payload can be populated later.
-
We spawn a process which can proceed to perform the background work. That process is responsible for making progress on the background work and eventually updating the database record with the final response or error payload for the operation. The same process is also responsible for periodically updating the timeout deadline timestamp for the operation in the database as long as progress is being made on the operation.
-
Respond to the initiating RPC with a reference to the newly created operation record. This allows the client to poll the operation status going forward.
When the client gets an operation resource name in the response, it
can start polling the operation for completion. As long as progress is
being made, the updated database record keeps the polling process from
seeing a deadline exceeded timeout. If the background worker actually
becomes unavailable or stops making progress, then the operation
deadline in the database will not get updated and eventually the
polling process will see the job timeout. On the other hand, in the
normal case, the polled operation will show as done == false until
the background worker runs to completion and updates the record with a
response payload. At that point, polling the operation status will
return done == true and the response payload will be available to
the client in the response field.
With this design, we’ve made the client yet more complicated. The new flow, starting from the import RPC request, looks like:
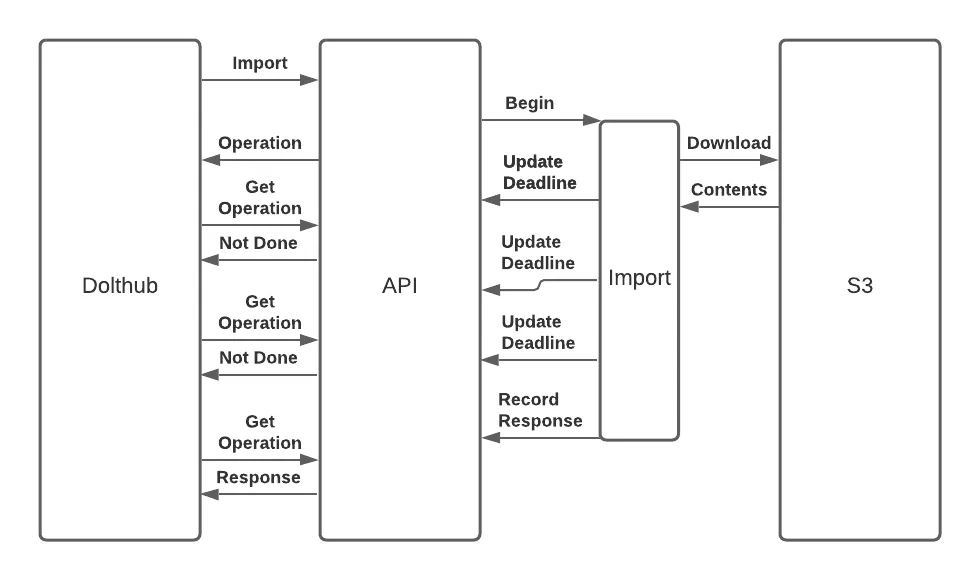
But it is worth it to achieve our goal of decoupling the import processing lifecycle from the lifecycle of a single synchronous RPC. Luckily, the complexity on the client can be managed. The entire flow, starting from getting the file upload location all the way to seeing the polled operation as done, can be placed behind an implementation which looks very similar to the previous synchronous RPC invocation.
Conclusion and Future Work#
By moving the import file contents and the importing processing itself out-of-band, we have decoupled the import file size limit and the processing resource limits from the lifecycle of the import RPC itself, which is a great thing since we want to iterate on these limits going forward. But you’ll see above that our import file limit is still 128MB, which could definitely be improved upon. We have more work to do on both the frontend and the backend to make larger imports possible and ergonomic.
For example, as part of the file upload on the frontend we calculate a cryptographic hash of the uploaded file’s contents. But our implementation to calculate the hash currently takes place synchronously on the UI thread with no incrementality. That means choosing a very large file in your browser can potentially lock up the UI thread for a bit. It’s easy to move the work to be incremental so that the UX for a user initially selecting a large file is less jarring.
The biggest changes needed to support even larger file uploads are in our implementation of the background import process itself. Currently the import results are buffered entirely in memory before being written out the Dolt repository as a new commit. This was the simplest thing that could possibly work and it does work for the current supported use cases, but it represents our next bottleneck to tackle as we grow edit on the web functionality. For now, we encourage you to try out one of the easiest ways to import data into a Dolt repository by creating a new repository and choosing “upload file” from the repository’s page.