
Introduction#
In November, shortly after the election, we published an analysis of Pennsylvania ballot data provided by the Pennsylvania Department of State. The purpose of the analysis was to determine if there was any truth to claims of irregularities being made on the internet. One such claim was completely debunked, but another actually appeared to have merit. Shortly after publication, Pennsylvania revoked public access to the data. An astute reader recently contacted us to inform us that the data was back online. We were curious to see if Pennsylvania had changed or updated the data during its hiatus. Indeed, they had.
This blog post is an analysis of the changes that Pennsylvania introduced during their downtime.
Importing the new data#
To start, I went to the Pennsylvania open data site to export the latest ballot data. Then I followed the original import procedure to get the new revision into my local Dolt repository (again using a locally modified copy of Dolt to accept the MM/DD/YYYY style date strings).
% perl ./id.pl < pa-voters-2021-01-02.csv > pa-voters-2021-01-02-ids.csv
% dolt import -r pa pa-voters-2021-01-02-ids.csv
% dolt diff --summary
diff --dolt a/pa b/pa
--- a/pa @ nab6l4mn8bcb60fvokgcueq8a3qsedfl
+++ b/pa @ oqh2jmom8iulmqiokrv8qreitne0cglo
3 Rows Unmodified (0.00%)
0 Rows Added (0.00%)
13,450 Rows Deleted (0.43%)
3,085,252 Rows Modified (99.57%)
30,497,939 Cells Modified (82.02%)
(3,098,705 Entries vs 3,085,255 Entries)What’s going on here? Surely not nearly every row was modified by this change?
The issue is that this data is unkeyed, so we use the row number in the export file as the key instead — the perl script is what adds these row numbers. The newer export puts the rows in a different order, essentially renumbering them. This is an antagonistic use case for Dolt — it can’t actually tell which rows changed. They all look like they changed.
Keyless tables to the rescue#
Let’s see if we can do any better by using a newly release feature, keyless tables. Keyless tables lose the ability to track changes to individual rows, since without a key there’s no notion of row identity. But it can do a better job with diffs on fundamentally unkeyed data, like this export. So let’s go ahead and create unkeyed versions of the table and import both versions of the ballot data.
% dolt sql
# Welcome to the DoltSQL shell.
# Statements must be terminated with ';'.
# "exit" or "quit" (or Ctrl-D) to exit.
pa_voters> CREATE TABLE pa_unkeyed (
County_Name longtext,
Applicant_Party_Designation longtext,
Date_of_Birth datetime,
Mail_Application_Type longtext,
Application_Approved_Date datetime,
Application_Return_Date datetime,
Ballot_Mailed_Date datetime,
Ballot_Returned_Date datetime,
State_House_District longtext,
State_Senate_District longtext,
Congressional_District longtext
);
pa_voters> exit
Bye
% dolt table import -u pa_unkeyed \
2020_General_Election_Mail_Ballot_Requests_Department_of_State.csv
% dolt add .
% dolt commit -m "Added unkeyed version of Nov 6 ballots export"
% dolt table import -r pa_unkeyed pa-voters-2021-01-02.csv
% dolt add .
% dolt commit -m "2021-01-02 import for unkeyed data"Now let’s see if we can get a better idea of the size of the change:
% dolt diff --summary l8gde0bou0983pqf0q5u8thds5nm6ee5 4f3gj32b764gsitdruoj606r48tt3dsm
diff --dolt a/pa_unkeyed b/pa_unkeyed
--- a/pa_unkeyed @ 10kd1mbt2i8q67on0epomqfvkla0s8ai
+++ b/pa_unkeyed @ nhbdb7nq9v40brlt7hg8u2qiqnej5919
155,789 Rows Added
169,239 Rows DeletedA note on how diffs work for keyless tables: since without a key there’s no sense of row identity, Dolt can’t tell the difference between 1) modifying a row and 2) deleting that row and adding a new one. The two operations are isomorphic in terms of the final result. So in the above row summary, it could mean that literally 155,789 rows were added, and then separately 169,239 rows were deleted. But this doesn’t seem likely. It could also be true that 155,789 rows were modified, then an additional (169,239 - 155,789) rows were deleted. And this would make sense, considering that the second data export contains 13,450 fewer rows than the original. But without much closer inspection, there’s no way to be sure, and that’s a low of rows to examine.
Figuring out what changed#
Instead of poring over all 325,028 lines of changes, let’s see if we can write some queries to see what changed between the first export and the second.
We’ll start by running the queries from our original analysis over
again. For all of these analyses, we’ll be using 4 different commit
hashes that represent the export at different revisions in its
history. I retrieved them by running the dolt log command.
% dolt log -n 4
commit 4f3gj32b764gsitdruoj606r48tt3dsm
Author: Zach Musgrave <zach@dolthub.com>
Date: Mon Jan 04 13:38:34 -0800 2021
2021-01-02 import for unkeyed data
commit l8gde0bou0983pqf0q5u8thds5nm6ee5
Author: Zach Musgrave <zach@dolthub.com>
Date: Mon Jan 04 11:57:03 -0800 2021
Added unkeyed version of Nov 6 ballots export
commit i032sfgc0o4vkhupfrtvi93eigfkjscd
Author: Zach Musgrave <zach@dolthub.com>
Date: Sat Jan 02 20:10:05 -0800 2021
Updated with data retrieved from newly restored PA dept of State export. The data uses an artificial key (row number in CSV export) and the row order is not stable between revisions. Therefore the dolt diff between these two revisions is not very useful. Deeper analysis will be necessary to determine the actual differences. 13,450 fewer ballot records are in the newer export. What other differences there are is unclear as of yet.
commit qq0v5cf58b2lhl4pp6g1raiqjgs39rdh
Author: Zach Musgrave <zach@liquidata.co>
Date: Mon Nov 09 13:56:08 -0800 2020
Typo in README
The four commit hashes we care about are:
- qq0v5cf58b2lhl4pp6g1raiqjgs39rdh: The data we originally published, retrieved on Nov. 6, before it was pulled down by the state.
- i032sfgc0o4vkhupfrtvi93eigfkjscd: The data published by the state when it came back online, retrieved Jan. 2.
- l8gde0bou0983pqf0q5u8thds5nm6ee5: The Nov. 6 export, in unkeyed format. (Unkeyed tables were not available in Dolt at the time of this export).
- 4f3gj32b764gsitdruoj606r48tt3dsm: The Jan. 2 export in unkeyed format.
First let’s see if the number of very elderly voters changed. We’ll
use the dolt diff command with the -q flag to compare the results
of a query between two revisions of the database.
% dolt diff -q \
"select count(*) from pa where date_of_birth < '1935-11-05' and ballot_returned_date is not null;" \
qq0v5cf58b2lhl4pp6g1raiqjgs39rdh i032sfgc0o4vkhupfrtvi93eigfkjscd
+-----+----------+
| | COUNT(*) |
+-----+----------+
| < | 126766 |
| > | 128200 |
+-----+----------+So there are slightly more very elderly voters in the newer export of the data, abot 1,500 more. This probably reflects delays in reporting ballot return dates, but who can say.
Next, let’s see what happened to the time-traveling ballots.
% dolt diff -q "select count(*) from pa where Ballot_Returned_date < Ballot_mailed_date;" \
qq0v5cf58b2lhl4pp6g1raiqjgs39rdh i032sfgc0o4vkhupfrtvi93eigfkjscd
+-----+----------+
| | COUNT(*) |
+-----+----------+
| < | 23305 |
| > | 181 |
+-----+----------+That’s interesting. They fixed the glitch!

Nothing inspires confidence in our institutions like taking open data offline, altering it, and then bringing it back online with no explanation of what you changed or why!
In all seriousness: they probably did actually fix a glitch in the original data. Twitter user Eppie Vojt published a great thread where he analyzed the time-traveling ballot data himself and looked for non-fraud explanations. It’s worth a read to see his methodology. For example, he determined that Lehigh County recorded around 65,000 ballots going out on Oct. 19, but actually sent them out on Oct. 6, according to a local press release.
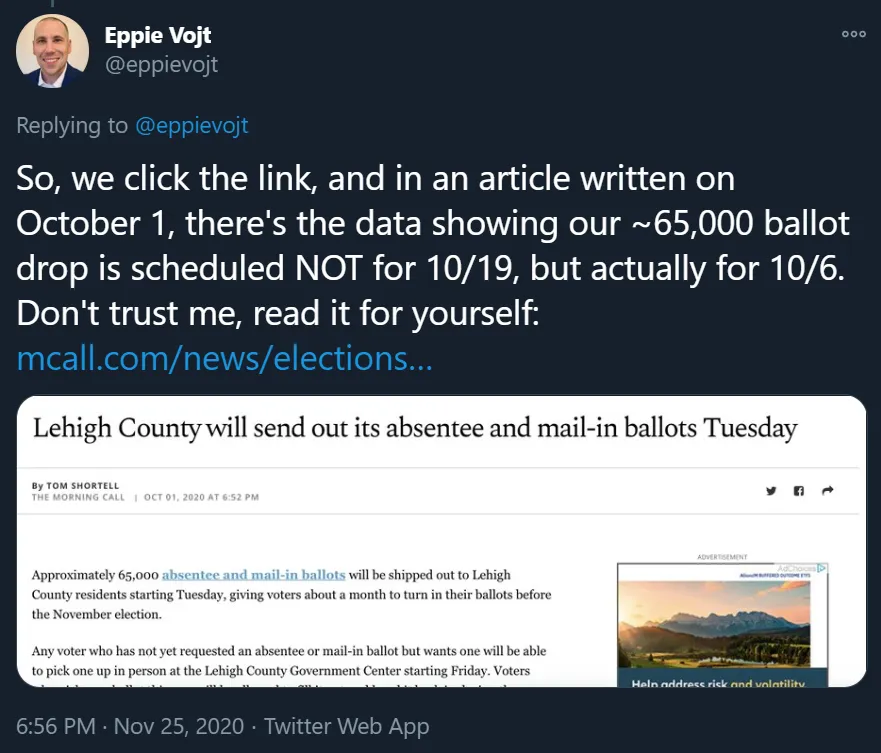
Let’s run the same query he used to see if this indeed accounts for some of the difference in the updated data.
% dolt diff -q \
"select ballot_mailed_date, count(*) as ballots
from pa where ballot_mailed_date is not null
and ballot_returned_date is not null
and county_name = 'LEHIGH' group by 1 order by 1" \
qq0v5cf58b2lhl4pp6g1raiqjgs39rdh i032sfgc0o4vkhupfrtvi93eigfkjscd
+-----+---------------------+---------+
| | Ballot_Mailed_Date | ballots |
+-----+---------------------+---------+
| < | 2020-09-17 00:00:00 | 360 |
| > | 2020-09-17 00:00:00 | 378 |
| < | 2020-09-18 00:00:00 | 100 |
| > | 2020-09-18 00:00:00 | 101 |
| < | 2020-09-21 00:00:00 | 1 |
| > | 2020-09-21 00:00:00 | 2 |
| < | 2020-09-25 00:00:00 | 14 |
| > | 2020-09-25 00:00:00 | 11766 |
| < | 2020-10-01 00:00:00 | 19 |
| > | 2020-10-01 00:00:00 | 22 |
| < | 2020-10-02 00:00:00 | 7 |
| > | 2020-10-02 00:00:00 | 22 |
| < | 2020-10-05 00:00:00 | 9 |
| > | 2020-10-05 00:00:00 | 14 |
| < | 2020-10-07 00:00:00 | 1 |
| > | 2020-10-07 00:00:00 | 2 |
| < | 2020-10-08 00:00:00 | 10 |
| > | 2020-10-08 00:00:00 | 12 |
| < | 2020-10-09 00:00:00 | 1 |
| > | 2020-10-09 00:00:00 | 2 |
| < | 2020-10-10 00:00:00 | 4 |
| > | 2020-10-10 00:00:00 | 5 |
| + | 2020-10-12 00:00:00 | 4 |
| < | 2020-10-13 00:00:00 | 2 |
| > | 2020-10-13 00:00:00 | 14 |
| < | 2020-10-15 00:00:00 | 1308 |
| > | 2020-10-15 00:00:00 | 1406 |
| < | 2020-10-16 00:00:00 | 36 |
| > | 2020-10-16 00:00:00 | 27 |
| < | 2020-10-19 00:00:00 | 64977 |
| > | 2020-10-19 00:00:00 | 54758 |
| < | 2020-10-20 00:00:00 | 178 |
| > | 2020-10-20 00:00:00 | 172 |
| < | 2020-10-21 00:00:00 | 1246 |
| > | 2020-10-21 00:00:00 | 1528 |
| < | 2020-10-22 00:00:00 | 921 |
| > | 2020-10-22 00:00:00 | 1134 |
| < | 2020-10-23 00:00:00 | 764 |
| > | 2020-10-23 00:00:00 | 873 |
| < | 2020-10-24 00:00:00 | 821 |
| > | 2020-10-24 00:00:00 | 1103 |
| < | 2020-10-26 00:00:00 | 806 |
| > | 2020-10-26 00:00:00 | 1128 |
| < | 2020-10-27 00:00:00 | 689 |
| > | 2020-10-27 00:00:00 | 808 |
| < | 2020-10-28 00:00:00 | 303 |
| > | 2020-10-28 00:00:00 | 535 |
| < | 2020-10-29 00:00:00 | 47 |
| > | 2020-10-29 00:00:00 | 52 |
| < | 2020-10-30 00:00:00 | 65 |
| > | 2020-10-30 00:00:00 | 67 |
| < | 2020-10-31 00:00:00 | 15 |
| > | 2020-10-31 00:00:00 | 12 |
| < | 2020-11-02 00:00:00 | 52 |
| > | 2020-11-02 00:00:00 | 62 |
| + | 2020-11-03 00:00:00 | 40 |
| + | 2020-11-16 00:00:00 | 2 |
| + | 2020-11-18 00:00:00 | 8 |
+-----+---------------------+---------+That’s not what I was expecting! The giant ballot mailing on 10/19 is still there, but it’s about 10,200 ballots smaller. And instead of a giant ballot mailing event on 10/6 as reported by local news outlets, we instead see an increase of over 11,700 ballots mailed out on 9/25.
So something doesn’t add up. Either the local news reporting was incorrect, or the original data was entered wrong, or this data was. Or any combination of these factors, I suppose. Let’s restrict our count to just the time-traveling ballots in the original export to see if we can figure out what’s going on. Instead of looking at the mailed date, let’s examine how many time-traveling ballots were received on a particular date.
To query the earlier data, we could checkout a branch at that commit
hash. But it’s easier to just query that revision directly in SQL with
the AS OF syntax.
% dolt sql -q \
"select ballot_returned_date, count(*) as ballots
from pa as of 'qq0v5cf58b2lhl4pp6g1raiqjgs39rdh'
where ballot_mailed_date > ballot_returned_date
and county_name = 'LEHIGH'
group by 1 order by 1"
+-------------------------------+---------+
| Ballot_Returned_Date | ballots |
+-------------------------------+---------+
| 2020-10-02 00:00:00 +0000 UTC | 17 |
| 2020-10-05 00:00:00 +0000 UTC | 6 |
| 2020-10-06 00:00:00 +0000 UTC | 3 |
| 2020-10-07 00:00:00 +0000 UTC | 3 |
| 2020-10-08 00:00:00 +0000 UTC | 4 |
| 2020-10-09 00:00:00 +0000 UTC | 14 |
| 2020-10-12 00:00:00 +0000 UTC | 266 |
| 2020-10-13 00:00:00 +0000 UTC | 589 |
| 2020-10-14 00:00:00 +0000 UTC | 1492 |
| 2020-10-15 00:00:00 +0000 UTC | 1955 |
| 2020-10-16 00:00:00 +0000 UTC | 2080 |
| 2020-10-17 00:00:00 +0000 UTC | 5482 |
| 2020-10-20 00:00:00 +0000 UTC | 6 |
+-------------------------------+---------+There doesn’t appear to be anything special about the 9/25 date. It’s about a week before the first of the time-traveling ballots starting arriving from Lehigh county. And they didn’t really start picking up their return rate until 10/14.
One more quick check. How many time-traveling ballots were there in Lehigh, before and after the revision?
% dolt diff -q \
"select count(*) as ballots from pa
where ballot_mailed_date > ballot_returned_date
and county_name = 'LEHIGH'" \
qq0v5cf58b2lhl4pp6g1raiqjgs39rdh i032sfgc0o4vkhupfrtvi93eigfkjscd
+-----+---------+
| | ballots |
+-----+---------+
| < | 11917 |
| > | 9 |
+-----+---------+Hmmm. That 11,908 ballot difference is almost the same as the 11,752 ballots mailed 9/25 that showed up in the second revision of the export. Further, almost all of the time-traveling ballots from Lehigh were mailed on 10/19:
% dolt sql -q \
"select ballot_mailed_date, count(*) as ballots
from pa as of 'qq0v5cf58b2lhl4pp6g1raiqjgs39rdh'
where ballot_mailed_date > ballot_returned_date
and county_name = 'LEHIGH' group by 1 order by 1"
+-------------------------------+---------+
| Ballot_Mailed_Date | ballots |
+-------------------------------+---------+
| 2020-10-19 00:00:00 +0000 UTC | 11911 |
| 2020-10-21 00:00:00 +0000 UTC | 6 |
+-------------------------------+---------+Is there a way we could tell if the 10/19 ballots had been “moved” to 9/25? As I mentioned before, this dataset doesn’t have row identity. But it does have something that’s close to unique: voter birth dates. What if we tried to match “missing” birth dates from 10/19 to the ones added to 9/25?
First let’s figure out the distribution of birthdays in the missing 10/19 ballots. To do this, I’m going to query the table at its two revisions, then join the two results together, subtracting out the difference. For brevity, I’m only going to look at the top 20 combinations of birth month and year.
pa_voters> select new.birth_month, new.count as new_count, old.count as old_count, old.count - new.count as missing
from (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa as of 'qq0v5cf58b2lhl4pp6g1raiqjgs39rdh'
where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-10-19')
group by 1) as old
join (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-10-19')
group by 1) as new
on old.birth_month = new.birth_month
order by missing desc
limit 20;
+-------------+-----------+-----------+---------+
| birth_month | new_count | old_count | missing |
+-------------+-----------+-----------+---------+
| 10-1951 | 99 | 141 | 42 |
| 9-1952 | 105 | 147 | 42 |
| 2-1947 | 86 | 127 | 41 |
| 11-1953 | 94 | 135 | 41 |
| 9-1951 | 106 | 147 | 41 |
| 11-1946 | 94 | 135 | 41 |
| 12-1953 | 112 | 152 | 40 |
| 6-1952 | 94 | 133 | 39 |
| 8-1953 | 97 | 135 | 38 |
| 10-1947 | 93 | 131 | 38 |
| 11-1951 | 92 | 129 | 37 |
| 9-1954 | 108 | 145 | 37 |
| 1-1947 | 99 | 136 | 37 |
| 7-1947 | 104 | 140 | 36 |
| 8-1949 | 101 | 136 | 35 |
| 10-1950 | 98 | 133 | 35 |
| 12-1948 | 85 | 120 | 35 |
| 1-1951 | 98 | 133 | 35 |
| 7-1955 | 96 | 131 | 35 |
| 4-1953 | 84 | 119 | 35 |
+-------------+-----------+-----------+---------+Now let’s look at top 20 birth months for the (almost entirely new) batch of 9/25 ballots.
pa_voters> select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa
where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-09-25')
group by 1
order by 2 desc
limit 20;
+-------------+-------+
| birth_month | count |
+-------------+-------+
| 10-1951 | 43 |
| 9-1952 | 42 |
| 2-1947 | 40 |
| 11-1953 | 40 |
| 11-1946 | 40 |
| 12-1953 | 40 |
| 11-1954 | 39 |
| 9-1951 | 39 |
| 7-1947 | 37 |
| 6-1952 | 37 |
| 3-1950 | 37 |
| 8-1956 | 36 |
| 12-1946 | 36 |
| 9-1954 | 36 |
| 12-1948 | 36 |
| 9-1948 | 36 |
| 11-1951 | 36 |
| 10-1947 | 36 |
| 9-1953 | 36 |
| 1-1947 | 36 |
+-------------+-------+That looks very, very similar. Let’s run them side by side to compare. This is a 3-way join with no way to use indexes, but the result set is pretty small so it should return.
pa_voters> select new.birth_month,
new.count as new_count,
old.count as old_count,
old.count - new.count as missing,
added.count as added
from (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa as of 'qq0v5cf58b2lhl4pp6g1raiqjgs39rdh'
where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-10-19')
group by 1) as old
join (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-10-19')
group by 1) as new
on old.birth_month = new.birth_month
join (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa
where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-09-25')
group by 1
) as added
on old.birth_month = added.birth_month
order by missing desc
limit 20;
+-------------+-----------+-----------+---------+-------+
| birth_month | new_count | old_count | missing | added |
+-------------+-----------+-----------+---------+-------+
| 9-1952 | 105 | 147 | 42 | 42 |
| 10-1951 | 99 | 141 | 42 | 43 |
| 11-1946 | 94 | 135 | 41 | 40 |
| 11-1953 | 94 | 135 | 41 | 40 |
| 2-1947 | 86 | 127 | 41 | 40 |
| 9-1951 | 106 | 147 | 41 | 39 |
| 12-1953 | 112 | 152 | 40 | 40 |
| 6-1952 | 94 | 133 | 39 | 37 |
| 10-1947 | 93 | 131 | 38 | 36 |
| 8-1953 | 97 | 135 | 38 | 35 |
| 9-1954 | 108 | 145 | 37 | 36 |
| 11-1951 | 92 | 129 | 37 | 36 |
| 1-1947 | 99 | 136 | 37 | 36 |
| 7-1947 | 104 | 140 | 36 | 37 |
| 12-1948 | 85 | 120 | 35 | 36 |
| 10-1950 | 98 | 133 | 35 | 35 |
| 1-1951 | 98 | 133 | 35 | 33 |
| 7-1955 | 96 | 131 | 35 | 32 |
| 12-1946 | 97 | 132 | 35 | 36 |
| 4-1953 | 84 | 119 | 35 | 34 |
+-------------+-----------+-----------+---------+-------+It certainly looks like the rows missing from 10/19 were added to 09/25. But maybe we’re being tricked here. Maybe birth month distributions follow a well defined pattern for this county, so it’s just a coincidence that a random sample from two parts of the dataset correspond like this. To rule this out, let’s run the query again on a randomly sampled set of 11,752 ballots from Lehigh county.
pa_voters> select new.birth_month,
new.count as new_count,
old.count as old_count,
old.count - new.count as missing,
sample.count as sample
from (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa as of 'qq0v5cf58b2lhl4pp6g1raiqjgs39rdh'
where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-10-19')
group by 1) as old
join (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-10-19')
group by 1) as new
on old.birth_month = new.birth_month
join (
select birth_month, count(*) as count from
(select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month
from pa
where county_name = 'LEHIGH'
and ballot_returned_date is not null
limit 11752) as sample
group by 1
) as sample
on old.birth_month = sample.birth_month
order by missing desc
limit 20;
+-------------+-----------+-----------+---------+--------+
| birth_month | new_count | old_count | missing | sample |
+-------------+-----------+-----------+---------+--------+
| 9-1952 | 105 | 147 | 42 | 18 |
| 10-1951 | 99 | 141 | 42 | 26 |
| 11-1946 | 94 | 135 | 41 | 23 |
| 11-1953 | 94 | 135 | 41 | 21 |
| 2-1947 | 86 | 127 | 41 | 16 |
| 9-1951 | 106 | 147 | 41 | 24 |
| 12-1953 | 112 | 152 | 40 | 27 |
| 6-1952 | 94 | 133 | 39 | 19 |
| 8-1953 | 97 | 135 | 38 | 28 |
| 10-1947 | 93 | 131 | 38 | 21 |
| 11-1951 | 92 | 129 | 37 | 24 |
| 9-1954 | 108 | 145 | 37 | 23 |
| 1-1947 | 99 | 136 | 37 | 20 |
| 7-1947 | 104 | 140 | 36 | 17 |
| 1-1951 | 98 | 133 | 35 | 25 |
| 8-1949 | 101 | 136 | 35 | 18 |
| 4-1953 | 84 | 119 | 35 | 10 |
| 12-1948 | 85 | 120 | 35 | 19 |
| 7-1955 | 96 | 131 | 35 | 13 |
| 10-1950 | 98 | 133 | 35 | 21 |
+-------------+-----------+-----------+---------+--------+So it’s definitely not the case that the similarity in the birth month
distribution between the missing 10/19 ballots and the added 9/25
ballots is a sampling artifact. The county as a whole doesn’t match
the distribution of this subset at all. (Note that this query may
actually return slightly different results each time it is run,
because in the absence of an ORDER BY clause the order is undefined,
which means a different sample of 11,752 ballots will be chosen).
Finally, let’s see how this distribution of birth months compares to our time-traveling ballots mailed on 10/19 in the original export.
pa_voters> select new.birth_month,
new.count as new_count,
old.count as old_count,
old.count - new.count as missing,
timetravelers.count as timetravelers
from (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa as of 'qq0v5cf58b2lhl4pp6g1raiqjgs39rdh'
where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-10-19')
group by 1) as old
join (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa where county_name = 'LEHIGH'
and ballot_returned_date is not null
and ballot_mailed_date = timestamp('2020-10-19')
group by 1) as new
on old.birth_month = new.birth_month
join (
select concat(concat(month(date_of_birth), "-"), year(date_of_birth)) as birth_month, count(*) as count
from pa as of 'qq0v5cf58b2lhl4pp6g1raiqjgs39rdh'
where county_name = 'LEHIGH'
and ballot_mailed_date = timestamp('2020-10-19')
and ballot_returned_date < ballot_mailed_date
group by 1
) as timetravelers
on old.birth_month = timetravelers.birth_month
order by missing desc
limit 20;
+-------------+-----------+-----------+---------+---------------+
| birth_month | new_count | old_count | missing | timetravelers |
+-------------+-----------+-----------+---------+---------------+
| 9-1952 | 105 | 147 | 42 | 43 |
| 10-1951 | 99 | 141 | 42 | 43 |
| 11-1946 | 94 | 135 | 41 | 41 |
| 2-1947 | 86 | 127 | 41 | 40 |
| 11-1953 | 94 | 135 | 41 | 40 |
| 9-1951 | 106 | 147 | 41 | 41 |
| 12-1953 | 112 | 152 | 40 | 40 |
| 6-1952 | 94 | 133 | 39 | 37 |
| 10-1947 | 93 | 131 | 38 | 36 |
| 8-1953 | 97 | 135 | 38 | 36 |
| 11-1951 | 92 | 129 | 37 | 36 |
| 9-1954 | 108 | 145 | 37 | 38 |
| 1-1947 | 99 | 136 | 37 | 37 |
| 7-1947 | 104 | 140 | 36 | 37 |
| 1-1951 | 98 | 133 | 35 | 34 |
| 7-1955 | 96 | 131 | 35 | 33 |
| 12-1948 | 85 | 120 | 35 | 36 |
| 10-1950 | 98 | 133 | 35 | 35 |
| 4-1953 | 84 | 119 | 35 | 34 |
| 8-1949 | 101 | 136 | 35 | 35 |
+-------------+-----------+-----------+---------+---------------+Those are our time travelers, alright. So it sure seems to me like 10,000 or so ballots originally marked as being mailed out on 10/19, but returned before then, had their mail date backdated to 9/25 instead. This date doesn’t match the 10/6 mass ballot mailing date in Lehigh County referenced in several local newspapers. And besides that: most of the 65,000 ballots recorded as being mailed out on 10/19 are still there in the new export. It’s only the ones mailed out on 10/19 that were marked as returned before then that had their mailing date changed. If you disagree with this analysis, chat with us on Discord and tell me why it’s wrong. But it looks right to me.
Once again: there may be a totally boring and straightforward explanation for the original irregularity in the data and this new change. But the data was changed. Over 10,000 “time traveling” ballots in Lehigh county had their mailing dates backdated to the same day after the state department made the data private for several weeks.
I haven’t looked at the data for the other 2 counties that accounted for the lion’s share of time-traveling ballots. One of you can run that analysis once you tell me why mine is wrong.
Slicing the data other ways#
So far we’ve just focused on one county to see what changed between the two exports of this data, and see if the data corroborated the reasonable explanation that Eppie Vojt posited (it doesn’t). But what can the diff of this data tell us about the change as a whole?
To start with, the second export contains 13,450 fewer ballots than the first. Which ones were removed? This is hard to answer because we can’t tell the difference between a deleted row and a modified row. But matching up the birthdate distribution of voters should give us an idea as to which records got removed. This is left as an exercise for the reader.
But let’s consider the rows changed between revisions. To do so, we
can query the dolt_diff_pa_unkeyed table, a system table that
contains rows that differ between any two revisions of the table. Dolt
has a diff system table for every table stored in it, and it can be a
great way to inspect large changes between two revisions of a
database.
Let’s see if there was any pattern to the changes between applicant political party:
pa_voters> select coalesce(to_Applicant_Party_Designation, from_Applicant_Party_Designation) as party,
diff_type, count(*)
from dolt_diff_pa_unkeyed
where from_commit = 'l8gde0bou0983pqf0q5u8thds5nm6ee5'
and to_commit = '4f3gj32b764gsitdruoj606r48tt3dsm'
and party in ('D', 'R', 'NF', 'I')
group by 1,2
order by 3 desc;
+-------+-----------+----------+
| party | diff_type | COUNT(*) |
+-------+-----------+----------+
| D | removed | 94617 |
| D | added | 87434 |
| R | removed | 47094 |
| R | added | 42278 |
| NF | removed | 20444 |
| NF | added | 19413 |
| I | removed | 1924 |
| I | added | 1787 |
+-------+-----------+----------+So on net, it looks like about 7,000 democrat ballots were removed from the export, and about 5,000 republican ballots. And about twice as many democrat ballots were altered between exports as republican ballots. (Again assuming that an add / delete pair of row changes represent an edit to a single original row, which is hard to verify).
How does that compare to the data as a whole? Are there about twice as many democrat ballot requests as republicans?
pa_voters> select applicant_party_designation as party, count(*)
from pa as of 'qq0v5cf58b2lhl4pp6g1raiqjgs39rdh'
where party in ('D', 'R', 'NF', 'I')
group by 1 order by 2;
+-------+----------+
| party | COUNT(*) |
+-------+----------+
| I | 31605 |
| NF | 255412 |
| R | 788558 |
| D | 1947005 |
+-------+----------+More than twice as many democrats requested mail ballots. So nothing particularly suspicious about twice as many democrat edits between revisions.
What about congressional districts? Were edits concentrated in any of them?
pa_voters> select coalesce(from_congressional_district, to_congressional_district) as district, count(*)
from dolt_diff_pa_unkeyed
where from_commit = 'l8gde0bou0983pqf0q5u8thds5nm6ee5'
and to_commit = '4f3gj32b764gsitdruoj606r48tt3dsm'
group by 1
order by 2 desc;
+-----------------------------+----------+
| district | COUNT(*) |
+-----------------------------+----------+
| 5TH CONGRESSIONAL DISTRICT | 45533 |
| 7TH CONGRESSIONAL DISTRICT | 42808 |
| 6TH CONGRESSIONAL DISTRICT | 39704 |
| 1ST CONGRESSIONAL DISTRICT | 34729 |
| 3RD CONGRESSIONAL DISTRICT | 26609 |
| 4TH CONGRESSIONAL DISTRICT | 17757 |
| 2ND CONGRESSIONAL DISTRICT | 16131 |
| 14TH CONGRESSIONAL DISTRICT | 16124 |
| 8TH CONGRESSIONAL DISTRICT | 14475 |
| 16TH CONGRESSIONAL DISTRICT | 12765 |
| 9TH CONGRESSIONAL DISTRICT | 11445 |
| 11TH CONGRESSIONAL DISTRICT | 8695 |
| 10TH CONGRESSIONAL DISTRICT | 7338 |
| 12TH CONGRESSIONAL DISTRICT | 7259 |
| 17TH CONGRESSIONAL DISTRICT | 6672 |
| 13TH CONGRESSIONAL DISTRICT | 5866 |
| 18TH CONGRESSIONAL DISTRICT | 5660 |
| 15TH CONGRESSIONAL DISTRICT | 5440 |
| NULL | 18 |
+-----------------------------+----------+Some congressional districts are definitely over-represented in these edits. What happens if we add county into the analysis?
pa_voters> select coalesce(from_congressional_district, to_congressional_district) as district,
coalesce(from_county_name, to_county_name) as county, count(*)
from dolt_diff_pa_unkeyed
where from_commit = 'l8gde0bou0983pqf0q5u8thds5nm6ee5'
and to_commit = '4f3gj32b764gsitdruoj606r48tt3dsm'
group by 1,2
order by 3 desc
limit 20;
+-----------------------------+----------------+----------+
| district | county | COUNT(*) |
+-----------------------------+----------------+----------+
| 5TH CONGRESSIONAL DISTRICT | DELAWARE | 41453 |
| 6TH CONGRESSIONAL DISTRICT | CHESTER | 36194 |
| 7TH CONGRESSIONAL DISTRICT | LEHIGH | 35912 |
| 1ST CONGRESSIONAL DISTRICT | BUCKS | 32780 |
| 3RD CONGRESSIONAL DISTRICT | PHILADELPHIA | 26609 |
| 4TH CONGRESSIONAL DISTRICT | MONTGOMERY | 17498 |
| 2ND CONGRESSIONAL DISTRICT | PHILADELPHIA | 16131 |
| 11TH CONGRESSIONAL DISTRICT | LANCASTER | 7218 |
| 14TH CONGRESSIONAL DISTRICT | FAYETTE | 6440 |
| 18TH CONGRESSIONAL DISTRICT | ALLEGHENY | 5660 |
| 8TH CONGRESSIONAL DISTRICT | LUZERNE | 5401 |
| 16TH CONGRESSIONAL DISTRICT | BUTLER | 4947 |
| 14TH CONGRESSIONAL DISTRICT | GREENE | 4797 |
| 7TH CONGRESSIONAL DISTRICT | NORTHAMPTON | 4743 |
| 8TH CONGRESSIONAL DISTRICT | MONROE | 4056 |
| 10TH CONGRESSIONAL DISTRICT | DAUPHIN | 3988 |
| 17TH CONGRESSIONAL DISTRICT | ALLEGHENY | 3931 |
| 6TH CONGRESSIONAL DISTRICT | BERKS | 3510 |
| 9TH CONGRESSIONAL DISTRICT | BERKS | 3450 |
| 16TH CONGRESSIONAL DISTRICT | ERIE | 3398 |
+-----------------------------+----------------+----------+Definitely not equally distributed. Numbers two and three on this list, Chester and Lehigh Counties, are the two counties with the most time-traveling ballots in the original export. But the top, Delaware county, didn’t even make the top 10 in that regard. Neither did Philadelphia county. Very curious what the changes there are about. But that’s an analysis for another day.
Conclusion#
How can an open data project call itself open when it forces me to jump through this many hoops to answer a simple question: what did you change? Why am I speculating at motives and staring at tables of numbers like a Q anon believer? Why isn’t that information part of the data being distributed?
Dolt has a commit log for a reason. Every change anyone makes to the data is recorded with their name and a description of why it was made. If Pennsylvania had shipped their data in Dolt format, and had made many small commits explaining the needed corrections they were making as they were being made, I wouldn’t need to do any of this. I could simply examine the log, or the history for an individual cell, to see what changed and why. Instead I’m forced to be very creative, and I probably made mistakes in my interpretation that led me to an incorrect conclusion somewhere along the way. It didn’t have to be like this.
We built Dolt because we think distributing CSVs is fundamentally broken, and a better way to share data is possible. We think Dolt is the answer. Give it a try and see if you agree.
To run the example queries in this blog article yourself, you can clone the dataset from DoltHub here.
If you aren’t ready to download the tool or just want to ask questions, come chat with us on Discord. We’re always happy to hear from new customers!