Background#
This is a guest blog post by a member of the DoltHub community, detailing how they went about accumulating presidential tweets in Dolt. We are grateful to our community members for showing us ways of using Dolt we didn’t think of, and also helping us improve the product.
Dolt is a version controlled SQL database, and DoltHub is a collaboration and hosting platform for Dolt databases. You can instantly obtain a copy of the data discussed in this post with by installing Dolt, and running a simple clone command:
$ dolt clone alexis-evelyn/presidential-tweets
cloning https://doltremoteapi.dolthub.com/alexis-evelyn/presidential-tweets
71,037 of 71,037 chunks complete. 0 chunks being downloaded currently.Why Archive Tweets#
In the aftermath of the 2020 election President Trump has tweeted repeatedly about alleged election fraud. As a concerned citizen I decided that making these tweets available as would be in the public interest and started to explore ways of doing so.
How#
When the idea for this project came up, I had been exploring Dolt. Using Dolt would provide anyone who clones the database with a SQL interface onto the presidential tweets, allowing them to easily explore and analyze the data.
At first, I started off by creating my own copy of the tweets from The Trump Archive. I then turned that data into a CSV and imported the tweets into Dolt:
$ dolt sqlI created a table for Trumps tweets:
CREATE TABLE `trump` (
`id` bigint unsigned NOT NULL,
`date` datetime,
`text` longtext NOT NULL,
`device` longtext,
`favorites` bigint unsigned,
`retweets` bigint unsigned,
`quoteTweets` bigint unsigned,
`replies` bigint unsigned,
`isRetweet` tinyint,
`isDeleted` tinyint,
`repliedToTweetId` bigint unsigned,
`repliedToUserId` bigint unsigned,
`repliedToTweetDate` datetime,
`retweetedTweetId` bigint unsigned,
`retweetedUserId` bigint unsigned,
`retweetedTweetDate` datetime,
`expandedUrls` longtext,
`json` longtext,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;I then imported the archived data.
# The Command To Import Tweets From CSV
$ dolt table import -u trump latest-tweets.csvI found that this archive didn’t contain data such as the number of quote tweets or replies. In order to create a high quality archive, I needed to retrieve more complete data both about the past tweets that Trump shared, and a way to obtain new tweets.
I also wanted to import other presidential tweets, namely those by Joe Biden and Barrack Obama. I created separate tables for their tweets.
Collaboration#
After jumping on Discord and discussing with this with the folks at DoltHub, I ended up collaborating with a member of the DoltHub team on improving the schema for the archive. They suggested merging all the presidents together into one table and added a foreign key to associate tweets with a particular president. The foreign key can be retrieved from the presidents’ table. Having a merged table, as opposed to a table per president, allows us to make searching the tweets easier as well as making cross-analysis easier.
Whereas as previously I had views that pointed to a single president, the changes combining the Tweets allowed those views to query tweets by all presidents. This enriched the information available to my analysis tools, which I discuss in more detail at the end of the article.
This collaboration was mediated via DoltHub, you can see the merged pull request here, where the diff tab shows the changes that were incorporated.
Archiving Old Tweets#
As mentioned previously, the Trump Archive did not have all the relevant data about the tweets. Since I wanted to make a full archive of the tweet data for further analysis, I decided to download the tweets via the Twitter API. I first made a bash script which would export the tweet IDs in the database which did not have a JSON value stored with them. I then had the Python script import the list of IDs and then download the tweet.
I had the script read the header for the rate limit reset time when it received a non-JSON response, and then when it hit Twitter’s API rate limit backoff for some appropriate period of time before retrying. This process took almost three days.
Archiving New Tweets#
Once I had all the old tweets archived including the JSON response Twitter sent me, I added the ability for the script to lookup the tweets for itself. The script would first lookup the current president, then it would grab the president’s Twitter ID. The Twitter ID is a unique identifier for a Twitter account that never changes, even when the username is changed.
presidential_tweets> select twitter_user_id from presidents where `end_term` is null
+--------------------------------+
| id |
+------------------------------- +
| 1330291154194227202 |
+--------------------------------+After obtaining the Twitter ID and the president’s Twitter account ID. I then send in the Twitter ID to Twitter’s API through the API URL:
https://api.twitter.com/2/tweets/search/recentThis API url allows me to grab up to 100 tweets at a time. It is the same one The Trump Archive uses, so it’s missing the same data. As I’m able to download tweets using the same method I did for archiving the old tweets, I then just lookup the tweet JSON from the URL https://api.twitter.com/2/tweets/:id and parse that data instead.
-- Grab Latest ID From The Chosen Table - 25073877 is Donald Trump’s Account ID
select id from tweets where twitter_user_id=”25073877” order by id desc limit 1;Analyzing the Data#
It’s easy enough to play with the data yourself, for example if you want to see the last thing the president current present tweeted:
# Clone Dolt database
$ dolt clone alexis-evelyn/presidential-tweets && cd presidential-tweets
# Open SQL Shell To View Data
$ dolt sql
presidential_tweets> select * from tweets where twitter_user_id in ( (select twitter_user_id from presidents where `End Term` is null) order by id desc limit 1;Future Work#
I am currently working on an unbiased analysis tool under the name Rover. One can already interact with the bot on Twitter. The bot is set up to require someone explicitly mentioning @DigitalRoverDog in order to prevent spam.
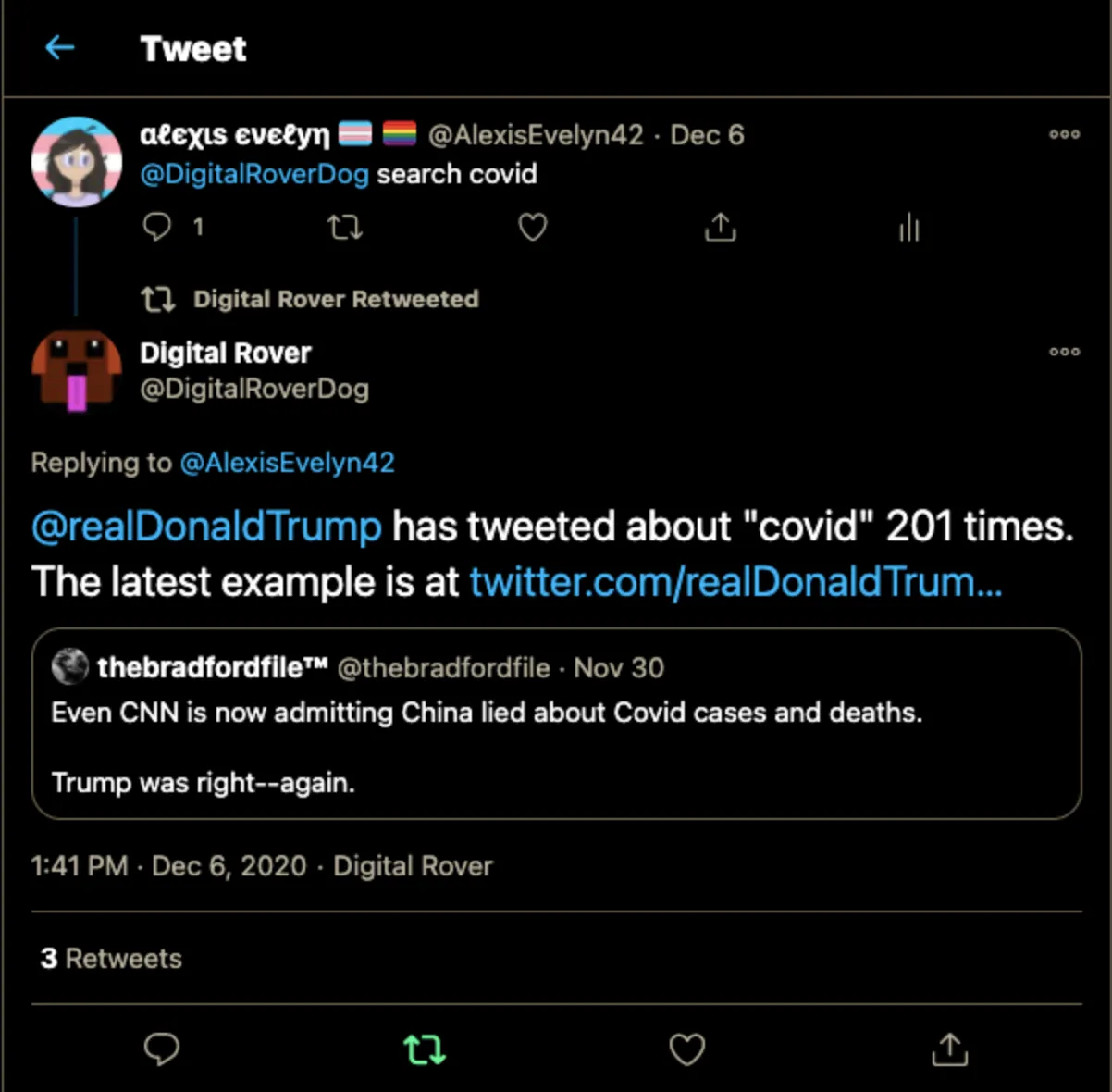
The repo can be found on Github for anyone interested in checking it out anyway. Currently, I am working on web support for Rover so more advanced analysis can be communicated through a medium that can handle more data than a tweet.
Conclusion#
I have written Python scripts which can be downloaded from this Github repo that retrieve and archive tweets from the current president in office. I have retroactively added existing tweets and have the archiver automatically poll and download new tweets every minute.
The archiver also has a Twitter account called @DigitalRoverDog which can be used to search for tweets from the current president and will also have a website to perform advanced analysis which cannot be communicated within a tweet.
About the Author#
Alexis Evelyn is a hobbyist software developer. She writes software to teach herself more about how to build applications she thinks should exist. The division that arose in the aftermath of the 2020 US General Election has motivated her to look for political applications. You can find her code on GitHub.