Version Controlled Databases: Defining a Category

"Database version control" and "version controlled database" are not the same thing. Version controlling your database refers to the practice of storing schema and schema modifications in a traditional source control system like Git. "Version controlled database" represents a class of append-only databases that offer traditional version control features like branch, diff, and merge across both schema and data. A Google search for "version controlled database" doesn't contain a single database product, but instead products and best practices for managing the schema of existing database solutions:

Using version control to manage your database schema is a very good thing, but it is not a "version controlled database." The goal of this post is to reclaim the term "version control database" for products that actually are databases with version control features. We are not unbiased here. We built Dolt, a SQL database with Git-style version control features. We think it will be the category defining product, and we want people to be able to find it.
Version Controlled Database vs Database Version Control
To make our case for reclaiming this term, it's worth being precise about the distinction we are trying to draw:
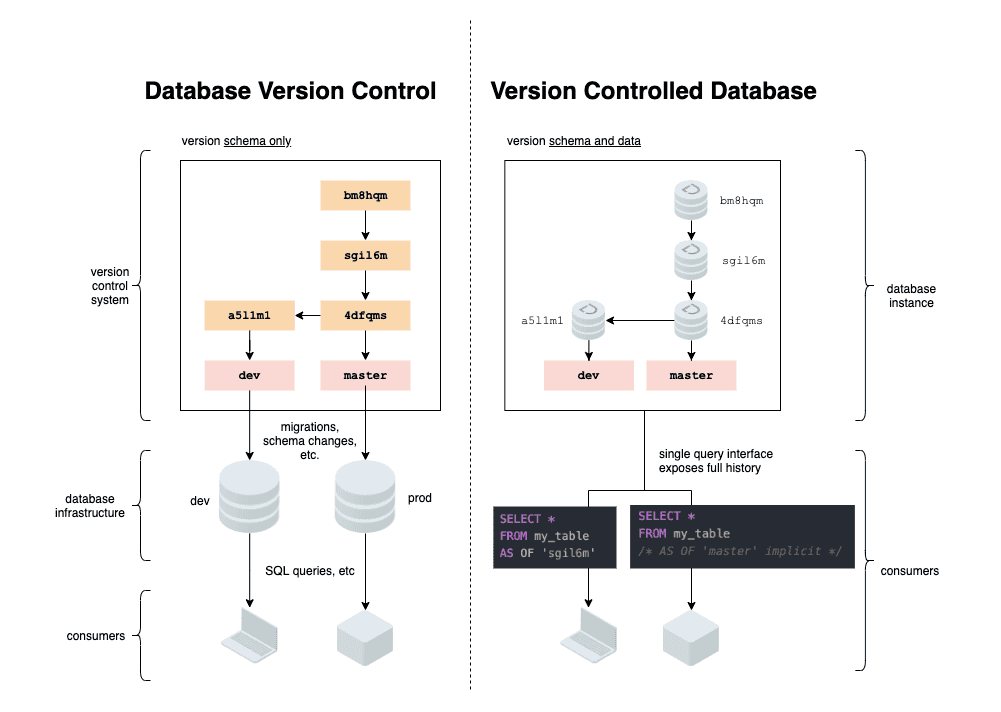
The diagram highlights the nature of the difference between a set of best practices and tools, and a database product:
- "Database version control" involves using a version control system (VCS) such as Git to version the schema and schema modifications of your database. The database itself knows nothing of its version history. There are many advanced tools and products for this.
- A "version controlled database" is a database that stores a full history of its own state, both data and schema.
This distinction brings us to the features that define "version controlled databases" as a category: the ability to store a history of its state, along with some version of branching, merging, and diffing across the stored history.
Why now?
In a blog entitled Software 2.0, Andrej Karpathy, a machine learning and artificial intelligence researcher and practitioner, describes a world where computer behavior is increasingly determined by data rather than code. You don't have to be an AI or ML cheerleader to recognize the increasing importance of data in determining the behavior of production systems. Ultimately, the value of data is increasing. Separately, storage costs of data have been in long run secular decline. These two factors combined with the advent of Merkle tree make it tractable to expose a full data history to a query interface, and therefore to build true version controlled databases.
Why adopt
We identified the fundamental features of a version controlled database as both the ability to store a history of the database state, as well as version control primitives such as branching, merging, and diffing.
Branching and Merging
Branching and merging are fundamental primitives for collaboration. They allow users to work concurrently against the same base dataset, and then resolve their differences in a principled and robust way. These capabilities differentiate version control databases from existing solutions by enabling users to collaborate on datasets without application layer code. The existing paradigm for databases imagines a single concept of state, and any tools that permit versioning and reconciliation need to be built into the application layer.
Diffing
Robust computation of "diffs" is not just useful for review, it is what enables version control systems to effectively implement operations like clone and pull. By implementing efficient diffs across their history, version control databases make for excellent data distribution formats. Users can clone and pull datasets, instantly querying strongly typed data using the database's query interface. The concept of "loading" data becomes redundant, and a whole class of errors defined by data type corruption is eliminated. It shouldn't be necessary to figure out what strings a data vendor uses to signify NULL, it should be native to the distribution format.
These features combine to provide much needed capabilities to data science and data engineering teams, and whoever else might have use for them. In particular
- collaboration becomes a first class consideration, with the ability for potentially hundreds of users to edit a dataset concurrently and robustly combine the results
- experiments and their results become completely reproducible by associating runs with a commit hash of the input data and result set
- distribution is transformed from a headache of parsing and loading various data formats which do not provide type guarantees to simply executing
cloneandpulloperations
In summary, we believe that version control databases can enable teams with powerful capabilities that they would otherwise have to invest considerable engineering resources in building and maintaining on top of existing database solutions.
Examples of Version Controlled Databases
If you've gotten to this point, it's likely that you are at least curious about what the landscape of products in this category of databases looks like. Naturally there are options other than Dolt, and for some use-cases those options might be the best fit.
TerminusDB
TerminusDB is a graph database, which means that data is described and queried in terms of graph data structures. It implements its own query language. TerminusDB is inspired by Git, and supports branching, merging and diffing in a Git-like interface.
Noms
Dolt is built on top of Noms. Noms is a Git-like distributed database that provides storage for structured objects defined by Go structs. Noms provides versioning and synchronization primitives for both the object definitions themselves, and values those objects take on. Users interact with Noms via Go code.
Irmin
Irmin is a storage layer agnostic database inspired by Git, and written in O'Caml. Users define objects in O'Caml that can then be stored using Git-like semantics. It is quite similar in spirit to Noms, but instead of Go structs, users describe, create, and update their data in O'Caml code.
Dolt
Dolt is our entry into this novel category of database. Dolt is a SQL database that implements the MySQL standard. Dolt leans heavily on Git, and implements branching, merging, and diff operations, and other Git primitives where relevant.
Why Dolt
The choice to implement the MySQL standard as a query interface strongly differentiates Dolt. Other version controlled databases, while interesting, require users to adopt a query interface that suits the database. Dolt takes the opposite position. We believe that SQL is the language of choice for the vast majority of our potential users, and we made the decision to adopt a query interface that suits our users.
As consequence of choosing the MySQL standard is compatibility with a huge ecosystem of tools that connect to Dolt out of the box. A quick look at our docs shows nine programming languages with tested MySQL connectors that work with Dolt. For folks that know SQL, and one of those nine programming languages, getting started with Dolt should be straight forward.
This design decision does not come without costs. The underlying commit graph storage is not a natural fit for a SQL query engine, and implementing a super set of MySQL on top of that storage layer is a huge technical commitment. Not only are we committed to matching everything MySQL can do, but we also have to design a set of functions to expose the commit graph in our SQL engine.
Conclusion
The software industry has long considered version control something that is done to databases, not a feature of databases. At DoltHub we consider "version controlled database" to be a product category, and Dolt is our attempt at a product that fits in that category.
Version control databases are not competitive with the practice of version controlling your database schema, or products that implement that practice. Instead they are a relatively novel category of databases differentiated by features that cater to users who care about capabilities that support collaboration, versioning, reproducibility, and distribution. By making these capabilities native to Dolt we hope to enable users to elevate the quality of their data infrastructure without the need to write and maintain application code, as well as open up possibilities that simply did not exist before.
If you want to talk to us about how you might use Dolt, or DoltHub, feel free to get in touch via email, or join us on Discord.