
Dolt is a SQL database with Git-like functionality, including clone, fork, push, pull, branch, and merge. DoltHub is a place on the internet for hosting, publishing, sharing and collaborating on Dolt databases. A few weeks ago, we announced support for forks on DoltHub. In this blog post, I wanted to walk through a quick example of what data collaboration on DoltHub can look like with forks.
Getting Started#
The first step is to have some dataset on DoltHub that you want to contribute to or improve. I started by browsing DoltHub repositories, in particular Featured, Recent and Starred repositories on the DoltHub front page.
I came across a DoltHub repository of US supreme court cases which included a table for supreme court justices. Because Justice Ruth Bader Ginsburg passed away recently, I wanted to make certain that the repository was up to date. Our CEO, Tim, had actually beaten me to updating entries for this particular news, but while I was looking through the data set I found some other missing data about supreme court justices that I wanted to improve.
Installing Dolt#
To collaborate on a DoltHub repository, you need Dolt itself to clone and edit the repository. You can install our newest release, either through the installer or through downloading the binary.
$ curl -OL https://github.com/dolthub/dolt/releases/download/v0.20.2/install.sh
100 2971 100 2971 0 0 5918 0 --:--:-- --:--:-- --:--:-- 5918
$ sudo bash ./install.sh
Downloading: https://github.com/dolthub/dolt/releases/download/v0.20.2/dolt-darwin-amd64.tar.gz
Installing dolt, git-dolt and git-dolt-smudge to /usr/local/bin.
$ dolt version
dolt version 0.20.2Forking the Repository#
The next step is to fork the repository we want to contribute to. I
click the Fork button next to the branch selector on the
repository’s page.
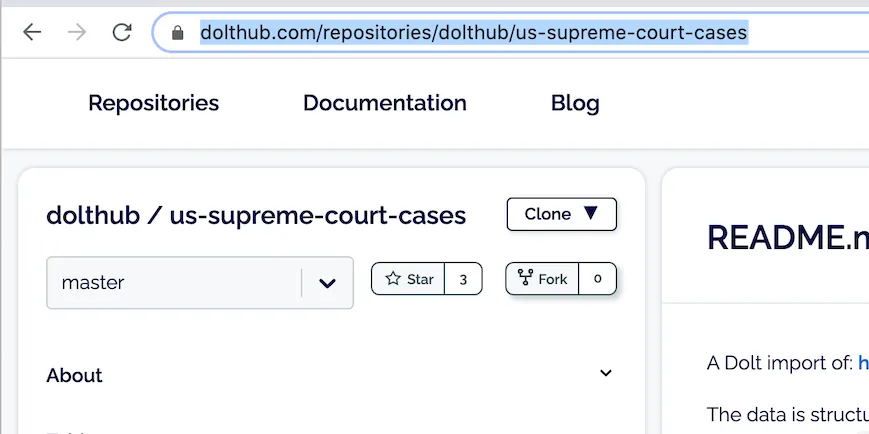
I choose my user account as the destination for the forked repository.
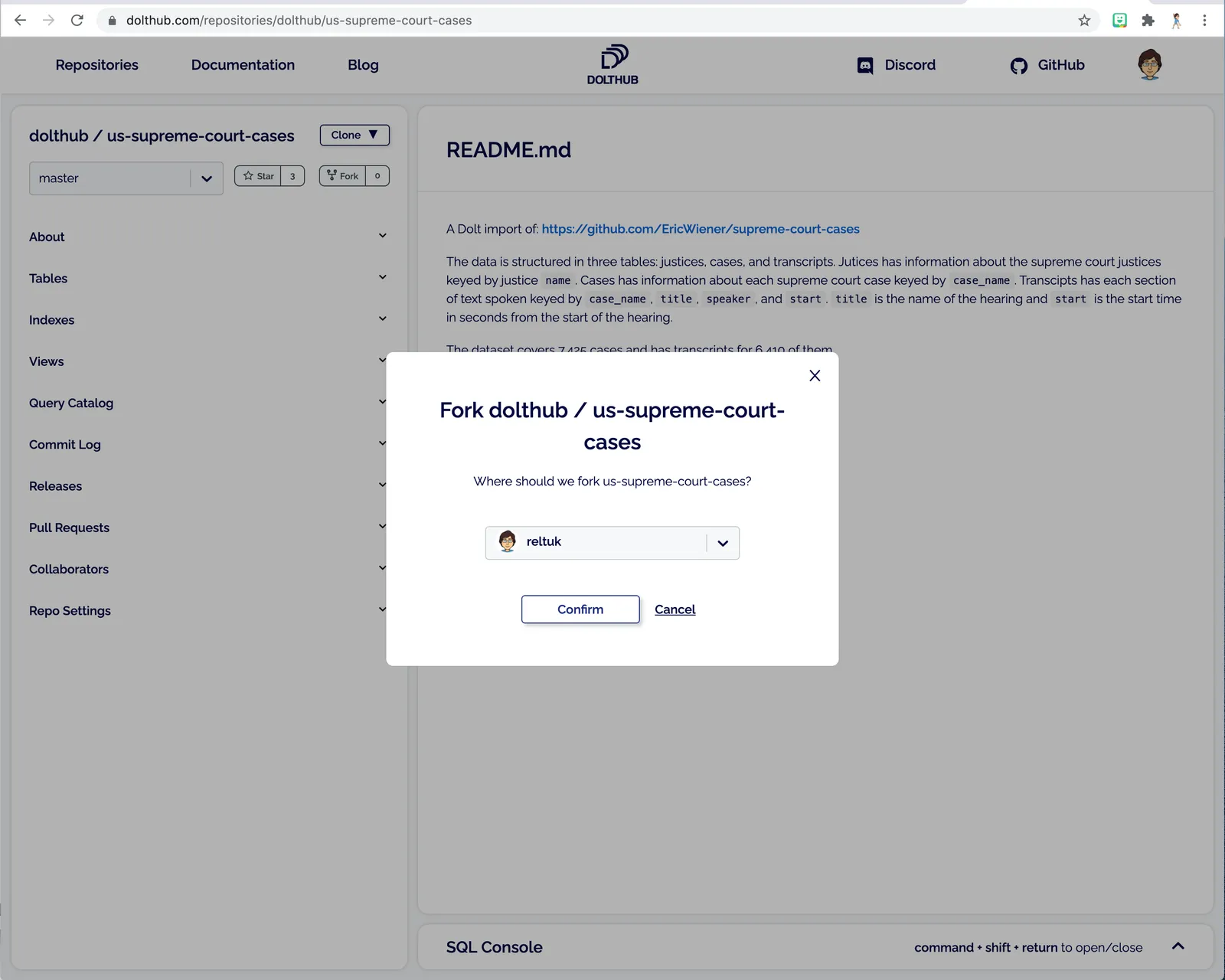
The result is my own fork of repository, where I can work without needing permissions to the original repository and without fear of impacting the original repository in any way.
Cloning my Fork#
Then I clone my forked repository to my local workstation.
$ dolt clone reltuk/us-supreme-court-cases
cloning https://doltremoteapi.dolthub.com/reltuk/us-supreme-court-cases
162,946 of 162,946 chunks complete. 0 chunks being downloaded currently.
$ cd us-supreme-court-cases
$ dolt ls
Tables in working set:
cases
justices
transcriptsMaking my Changes#
Once I have the repository locally, I can work with it exactly like a SQL database from a SQL shell. I drop into one and use SQL DML to update the specific fields I’m trying to correct.
$ dolt sql
# Welcome to the DoltSQL shell.
# Statements must be terminated with ';'.
# "exit" or "quit" (or Ctrl-D) to exit.
us_supreme_court_cases> update justices set succeeded_by = 'Neil Gorsuch' where name = 'Antonin Scalia';
Query OK, 1 row affected
Rows matched: 1 Changed: 1 Warnings: 0
us_supreme_court_cases> update justices set preceded_by = 'Antonin Scalia' where name = 'Neil Gorsuch';
Query OK, 1 row affected
Rows matched: 1 Changed: 1 Warnings: 0
us_supreme_court_cases> update justices set preceded_by = 'John M. Harlan' where name = 'Mahlon Pitney';
Query OK, 1 row affected
Rows matched: 1 Changed: 1 Warnings: 0
us_supreme_court_cases> update justices set reason_for_leaving = 'Retired' where name = 'Sandra Day O''Connor';
Query OK, 1 row affected
Rows matched: 1 Changed: 1 Warnings: 0
us_supreme_court_cases> update justices set reason_for_leaving = 'Retired' where name = 'David H. Souter';
Query OK, 1 row affected
Rows matched: 1 Changed: 1 Warnings: 0
us_supreme_court_cases> update justices set reason_for_leaving = 'Death' where name = 'Ruth Bader Ginsburg';
Query OK, 1 row affected
Rows matched: 1 Changed: 1 Warnings: 0
us_supreme_court_cases> update justices set reason_for_leaving = 'Retired' where name = 'Anthony M. Kennedy';
Query OK, 1 row affected
Rows matched: 1 Changed: 1 Warnings: 0We can even run some nice sanity checks on the fields we’re working on:
us_supreme_court_cases> select name, preceded_by from justices where preceded_by not in (select name from justices);
+------+-------------+
| name | preceded_by |
+------+-------------+
+------+-------------+
us_supreme_court_cases> select name, succeeded_by from justices where succeeded_by not in (select name from justices);
+------+--------------+
| name | succeeded_by |
+------+--------------+
+------+--------------+
us_supreme_court_cases> select reason_for_leaving, count(*) from justices group by reason_for_leaving;
+--------------------+----------+
| reason_for_leaving | COUNT(*) |
+--------------------+----------+
| Resigned | 16 |
| Retired | 35 |
| Death | 48 |
| <NULL> | 8 |
| Disabled | 4 |
| Promoted | 3 |
+--------------------+----------+After the changes are made to the database, I need to create a commit capturing and describing my changes.
$ dolt add .
$ dolt commit -m 'Adding some missing preceded_by and succeeded_by. Cleaning reason_for_leaving in a few places.'
commit aedot7h7isudonnfnlq97utf3a27rs9n
Author: Aaron Son <aaron@liquidata.co>
Date: Mon Oct 05 10:44:07 -0700 2020
Adding some missing preceded_by and succeeded_by. Cleaning reason_for_leaving in a few places.Opening the Pull Request#
The next step is to open the pull request on DoltHub. I start by pushing my changes up to my fork:
$ dolt push origin master:master
Tree Level: 16 has 11 new chunks of which 10 already exist in the database. Buffering 1 chunks.
Tree Level: 16. 100.00% of new chunks buffered.
Tree Level: 2 has 2 new chunks of which 1 already exist in the database. Buffering 1 chunks.
Tree Level: 2. 100.00% of new chunks buffered.
Tree Level: 1 has 6 new chunks of which 2 already exist in the database. Buffering 4 chunks.
Tree Level: 1. 100.00% of new chunks buffered.
Successfully uploaded 1 of 1 file(s).I browse to the parent repository, where I can open my pull request:
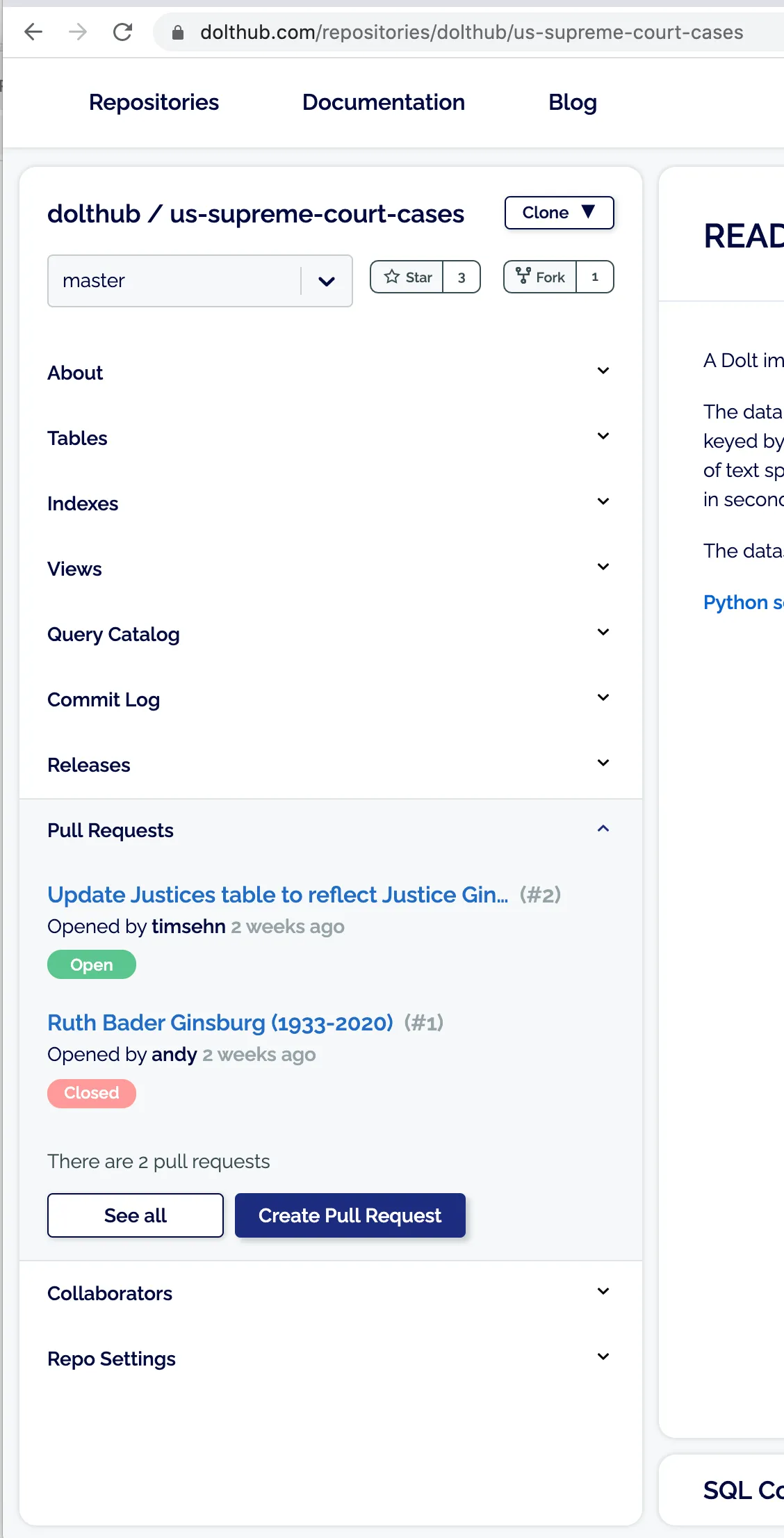
I choose my own repository as the from repository, and I choose the
branch I pushed to master, as the source.
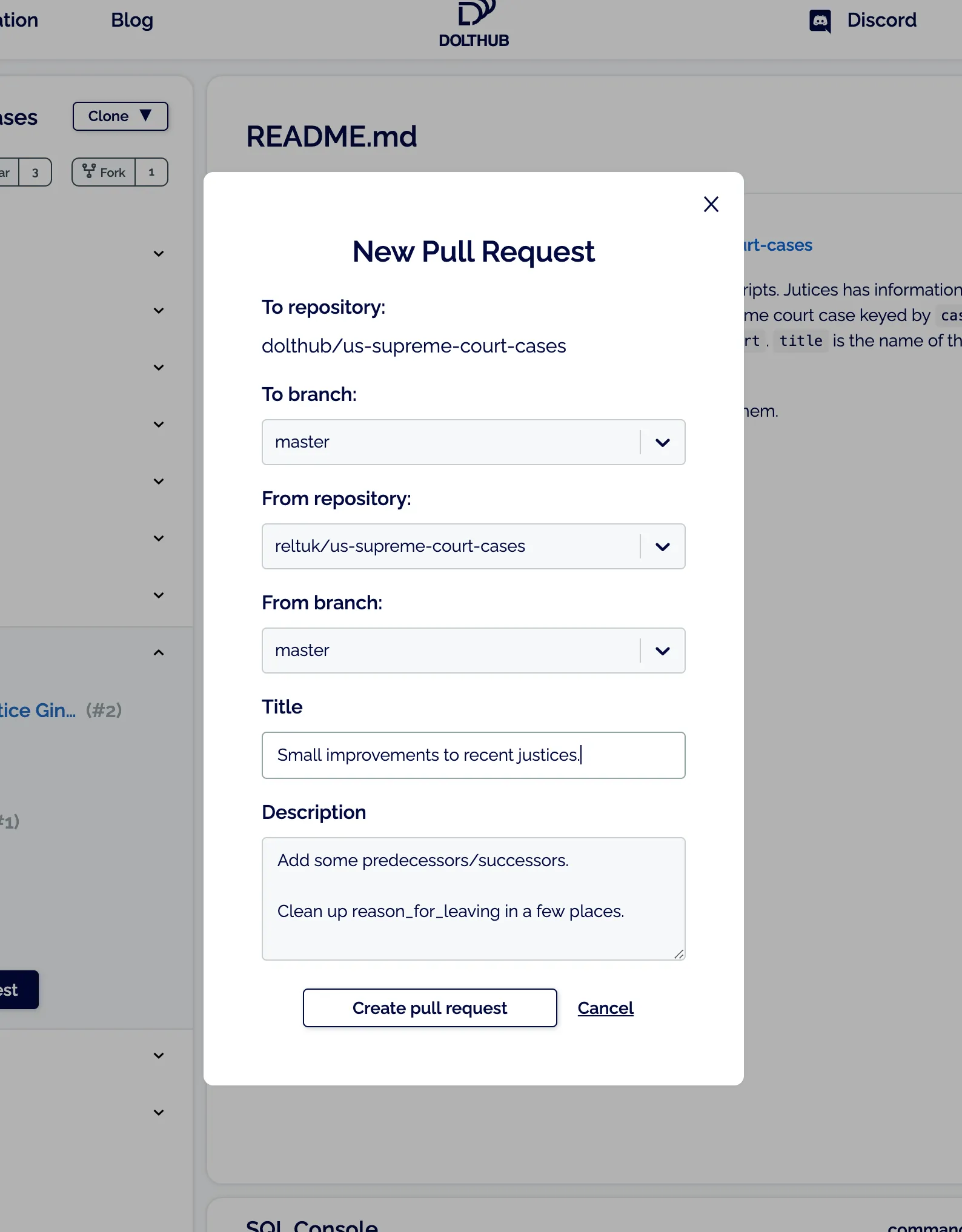
The result is the my newly created pull request.
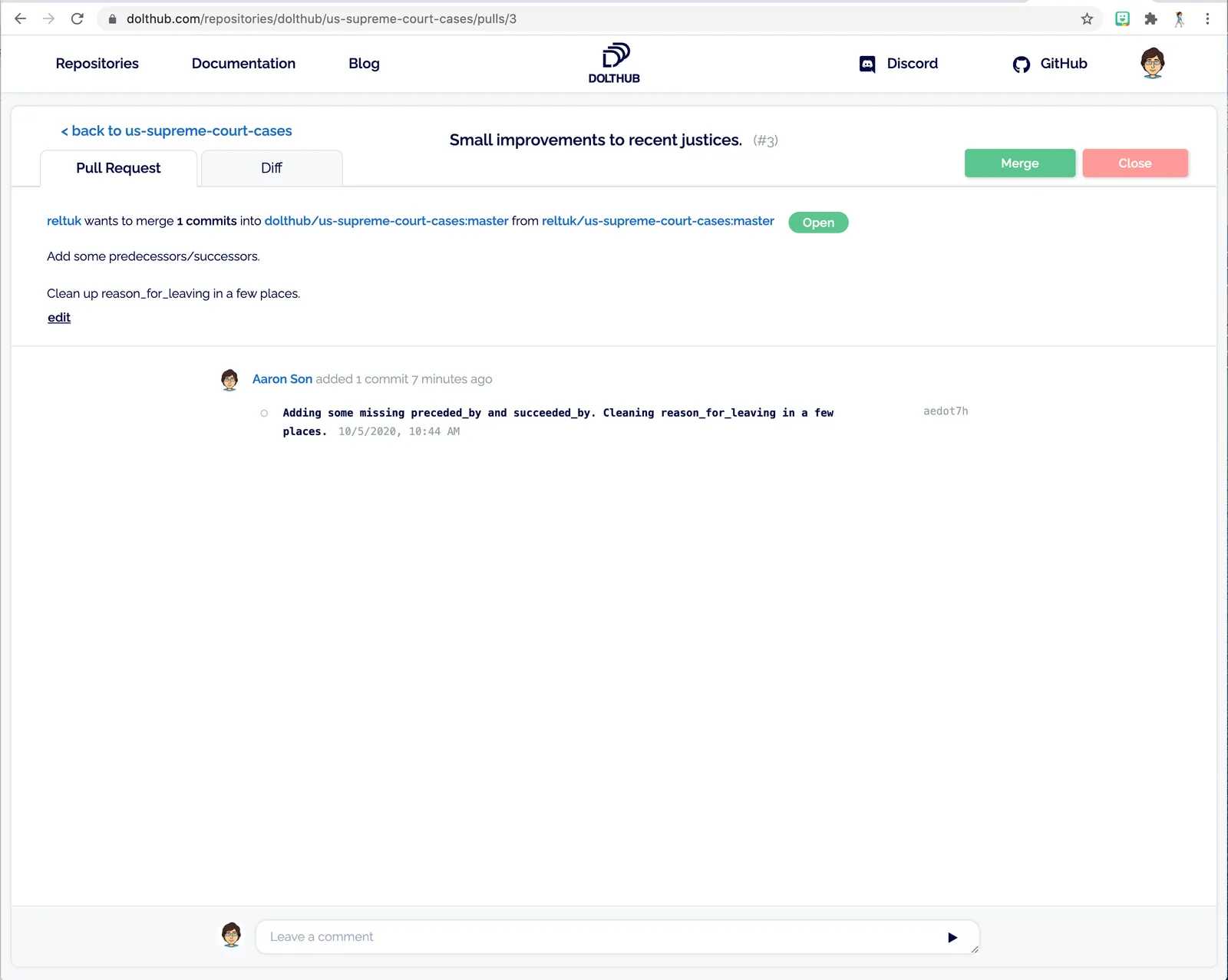
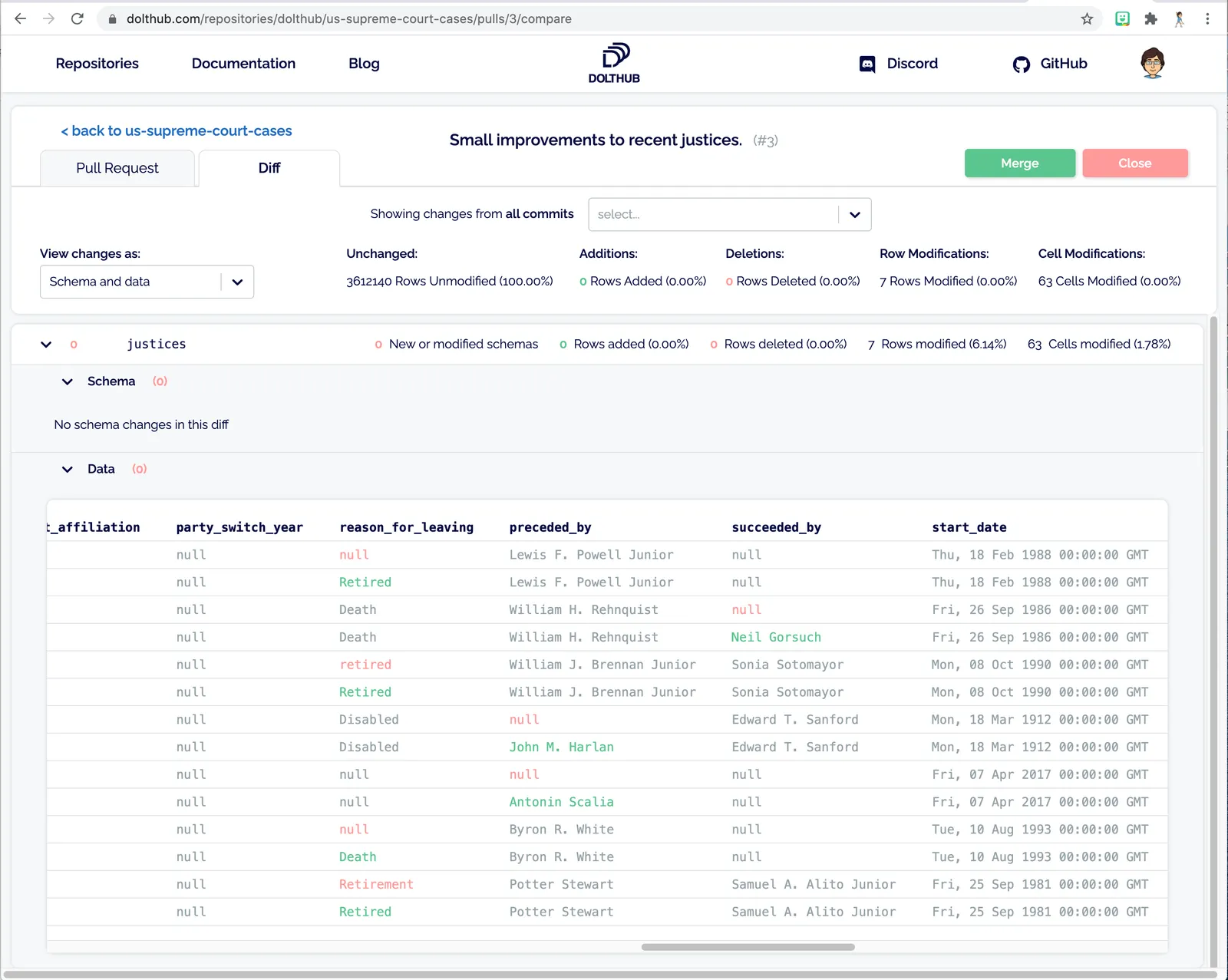
Including nice browseable diffs of the changes that I’m asking to merge.
Next Steps#
It’s up to the repository owner to choose whether to accept my changes
or not. In this case, if the repository owner wants to accept the
changes, they just need to merge my changes to master and the pull
request will close as Merged when they push master up to
dolthub/us-supreme-court-cases.
And that’s it. I now have an independent fork of
us-supreme-court-cases, where I can continue to do my work and push
any changes I might develop. I can setup my clone with an upstream
remote pointing at dolthub/us-supreme-court-cases and I can continue
to merge the changes that land in upstream’s master into my fork’s
master. The pull requests I open against the parent can be
individually evaluated for inclusion in the original project, and an
arbitrary number of contributors can engage in this process
simultaneously. If the original project maintainers have any questions
about my changes, they can easily merge the branch from my pull
request and run whatever sanity checks and queries they need to in
order to gain confidence in my contributions.
We think this workflow is absolutely awesome, and we think branch, merge and pull requests are fundamental to the future of data collaboration and open data projects. Come on over to DoltHub to host your own and contribute to existing data projects today.