Oracle Support in SQL Sync

Dolt is a relational database with Git-like version control features. In particular the underlying data storage format is a commit graph, and each commit represents the complete state (schema and data) of the database at a point in time. Doltpy, our Python API, provides users with tools to easily move data between their existing databases and Dolt. This post covers adding support for Oracle. We wanted to support Oracle because several customers asked for it. Given how widely adopted it is as a database solution, this is not surprising. Supporting Oracle proved more complicated than the other databases. Most of that complexity comes from Oracle having a model that differs substantially from Postgres and MySQL, as well as how long the database takes to actually startup. We cover how to abstract away this complexity in a clean test fixture in the final section using Docker.
Overview
Let's start with the goal: we want to provide a simple API for moving data from Dolt to Oracle, or from Oracle to Dolt. Let's say we want to get data from the revenue_estimates table in Oracle into Dolt for versioning, we want to write code like this:
from doltpy.etl.sql_sync import sync_from_dolt, get_dolt_target_writer, get_oracle_source_reader
sync_to_dolt(get_oracle_source_reader(oracle_engine),
get_dolt_target_writer(dolt_repo),
{'revenue_estimates': 'revenue_estimates'}We need some objects for managing database connections, which are defined as follows:
from doltpy.core import Dolt
import sqlalchemy as sa
import cx_Oracle
# Setup objects to represents source and target databases, start Dolt SQL Server
dolt = Dolt.init('my-org/estiamtes')
dolt.sql_server()
engine = create_engine('oracle+cx_oracle://', creator=_oracle_connection_helper)
def _oracle_connection_helper:
return cx_Oracle.connect('oracle_user', 'oracle_pwd', '{}:{}/{}'.format('oracle_host', 1521, 'oracle_db'))In order to incorporate Oracle into our SQL Sync tooling we need to verify that we can "round trip" data from Dolt to Oracle, and from Oracle to Dolt. We do the same for Postgres and MySQL. In practice this means we need instances of each of these databases running, and available to our test harness. The most repeatable and portable way we have found is to use pytest-docker to run a containerized instance of each database implementation. The architecture looks something like this:
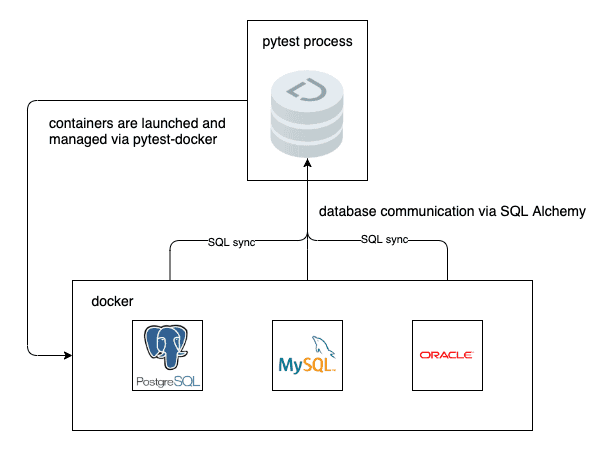
To achieve this we need three things:
- a Docker image available that stands up an Oracle instance
- augment our test harness to run that image, and populate it with a test table
- code to execute and test the sync
We will examine them in reverse order, starting with the implementation, as that's closest to the user value the feature delivers.
Implementation
Once Oracle was incorporated into our test harness, actually reading and writing from it was straightforward, and done via SQL Alchemy. We focus on the issues caused by how SQL Alchemy maps between higher level types and Oracle types. One main benefit of SQL Alchemy is the SQL Expression Language that abstracts over multiple database implementations, something we blogged about. In most cases this takes care of translating between database implementation specific types by providing a higher level set of types. A concrete example is how this higher level expression language allows us to use a single definition of a test table, making our code cleaner and more readable, as well as reducing database implementation specific boilerplate:
from sqlalchemy.types import Integer, DateTime, String, Text, Float, Date
TEST_TABLE_METADATA = Table(TABLE_NAME,
MetaData(),
Column('first_name', String(256), primary_key=True),
Column('last_name', String(256), primary_key=True),
Column('playing_style_desc', Text),
Column('win_percentage', Float),
Column('high_rank', Integer),
Column('turned_pro', DateTime),
Column('date_of_birth', Date))In the snippet above engine is a SQL Alchemy object that manages a database connection pool. Passing that engine to a call to create the table we just defined will execute the generated query against the corresponding database instance. This is exactly what we do to create a test table in our containerized Oracle instance:
TEST_TABLE_METADATA.metadata.create_all(engine)The type mapping issue arises because SQL Alchemy translates both sqlalchemy.types.Date and sqlalchemy.types.DateTime to Oracle's DATE type. This is clearly a bug, as this amounts to "destructive" type coercion, and in fact the library should not permit writes of datetime.datetime Python objects to DATE without at least warning the user of information loss. We plan to implement fixes to SQL Alchemy, and push them back to that project as a wider benefit to the community.
For the purposes of using the data sync, however, this is not an issue. This code is purely for creating a test table, and we do not yet support schema sync in Oracle. We work around this in our test suite.
Test Harness
In order for us to execute the SQL Alchemy expressions above, we need to incorporate a running Docker image that exposes an Oracle instance to our test harness. We launch our containers via pytest-docker, a pytest plugin that wraps docker-compose. This allows us to define Docker services using dictionaries which are in turn translated into YAML:
@pytest.fixture(scope='session')
def docker_compose_file(tmpdir_factory, mysql_service_def, postgres_service_def, oracle_service_def):
compose_file = tmpdir_factory.mktemp('docker_files').join('docker-compose.yml')
compose_conf = {
'version': '2',
'services': {
'mysql': mysql_service_def,
'postgres': postgres_service_def,
'oracle': oracle_service_def
}
}
with compose_file.open('w') as f:
yaml.dump(compose_conf, stream=f)
return compose_file.strpathNote that this fixture itself depends on a test fixture called oracle_service_def which specifies how to launch the Oracle service definition. Again, this fixture returns a dictionary, which is incorporated into docker_compose_file as follows:
@pytest.fixture(scope='session')
def oracle_service_def():
return {
'image': 'oscarbatori/oracle-database:18.4.0-xe-quick',
'container_name': ORACLE_CONTAINER_NAME,
'ports': ['{port}:{port}'.format(port=ORACLE_LISTENER_PORT),
'{port}:{port}'.format(port=ORACLE_OEM_EXPRESS_PORT)]
}
In the following section we detail how to get an Oracle image that takes a reasonable amount of time to start (around a minute). That is still too slow for pytest which will throw errors when our fixtures for fetching a SQL Alchemy engine object run. We can put some retry logic around those calls to make the fixture swallow errors for some reasonable period of time until it obtains a connection:
@pytest.fixture
def oracle_engine(docker_ip, docker_services) -> Engine:
engine = create_engine('oracle+cx_oracle://', creator=lambda: _oracle_connection_helper(docker_ip))
@retry(delay=10, tries=12, exceptions=(sqlalchemy.exc.DatabaseError))
def verify_connection():
conn = engine.connect()
conn.close()
return engine
return verify_connection()
def _oracle_connection_helper(host):
return cx_Oracle.connect(ORACLE_USER, ORACLE_PWD, '{}:{}/{}'.format(host, ORACLE_LISTENER_PORT, ORACLE_DB))Our test harness is now augmented to fire up a service running an instance of Oracle XE. In order to get this container running we needed to create the actual image, as unlike Postgres and MySQL, there was not a freely available on one on Docker Hub.
Building an Image
Up until this point we have assumed the instance of an Oracle image. This proved a little tricky in practice. We found a GitHub repository containing some tools for building images here. We cloned the repo, and ran the following from the appropriate subdirectory:
$ /buildDockerImage.sh -v 18.4.0 -xAfter about twenty minutes, this produced an image that we could then use to run a container in our development in environment, in this case locally on OSX:
$ docker run --name test_oracle \
-p 1521:1521 -p 5500:5500 \
-e ORACLE_PWD=oracle_password \
oracle/database:18.4.0-xeUnfortunately, it takes about 15 minutes for the Oracle database to get into a state were it is accepting connections. This is far too slow for a test suite, as it would make a single test run take more than fifteen minutes. Slow tests discourage developers from using them, increasing the the likelihood of error. Fortunately, Docker provides functionality for creating an image from a running container (credit to this blog post for inspiration). The following command creates a snapshot of the container we fired up in our dev environment in the previous step:
$ docker commit --author "Oscar Batori me@my-email.com" --message "Fast Oracle XE snapshot" oscarbatori/oracle-database:18.4.0-xe-quickThe image could then be started as follows:
docker run --name test_oracle \
-p 1521:1521 -p 5500:5500 \
-e ORACLE_PWD=oracle_password \
oscarbatori/oracle-database:18.4.0-xe-quickWe now had an image that could present stand up a running Oracle instance in under a minute, allowing us to build the test harness and tests detailed above on top of it.
Conclusion
In this post we covered how we incorporated Oracle into our doltpy.etl.sql_sync, a module of the Dolt's Python API, Doltpy, that provides utilities to users who would like to use Dolt alongside existing relational database solutions. We hope that by supporting Oracle we will vastly increase the number of users who are able to capture the benefits for a version controlled SQL database while not having to abandon their existing tools. We have a SQL Sync guide in our doltpy repository.