
Dolt is a SQL database with Git-style versioning. DoltHub is a place on the internet to share Dolt databases.
We recently adopted Discord as a low friction way to interact with our customers. It’s been a really positive experiment. Our community is at about 50 people and a handful of people are very active. It’s been inspiring to see how customers are getting value from Dolt.
The subject of this blog article is one particular interaction we had with a user who was having an issue with Dolt. The interaction really displayed the power of distributed collaboration on databases using Dolt. It’s such a good example of the type of teamwork Dolt enables that we thought highlighting it might get people to try Dolt for themselves.
Dolt’s Unique Collaboration Advantage#
Dolt is the only database on the market you can branch and merge. Dolt is designed from the ground up to make merge operations efficient in storage and fast. The expectation with Dolt is that you can just clone the database on any operating system and the database will “just work”. This simple feature enables really powerful collaboration.
That’s all well and good, but what does that really mean for users? Well, it means hundreds of people can be editing the database at the same time, both schema and data, without impacting each other’s work. Everyone creates their own Dolt clone, makes a branch, and starts editing. You can compare your work against the known good copy and still get updates from the known good. When you are ready to merge your edits to the known good, you push your copy to DoltHub and open a Pull Request. Another person can review your changes and accept them into the known good. This is the standard workflow for editing code and we think it should be the standard for editing data as well.
Example#
This example all started with a bug in Dolt that prevented reusing table names. For a single release if you dropped a table and re-added one with the same name, Dolt would not allow you to add the new table. It would error with table already exists.
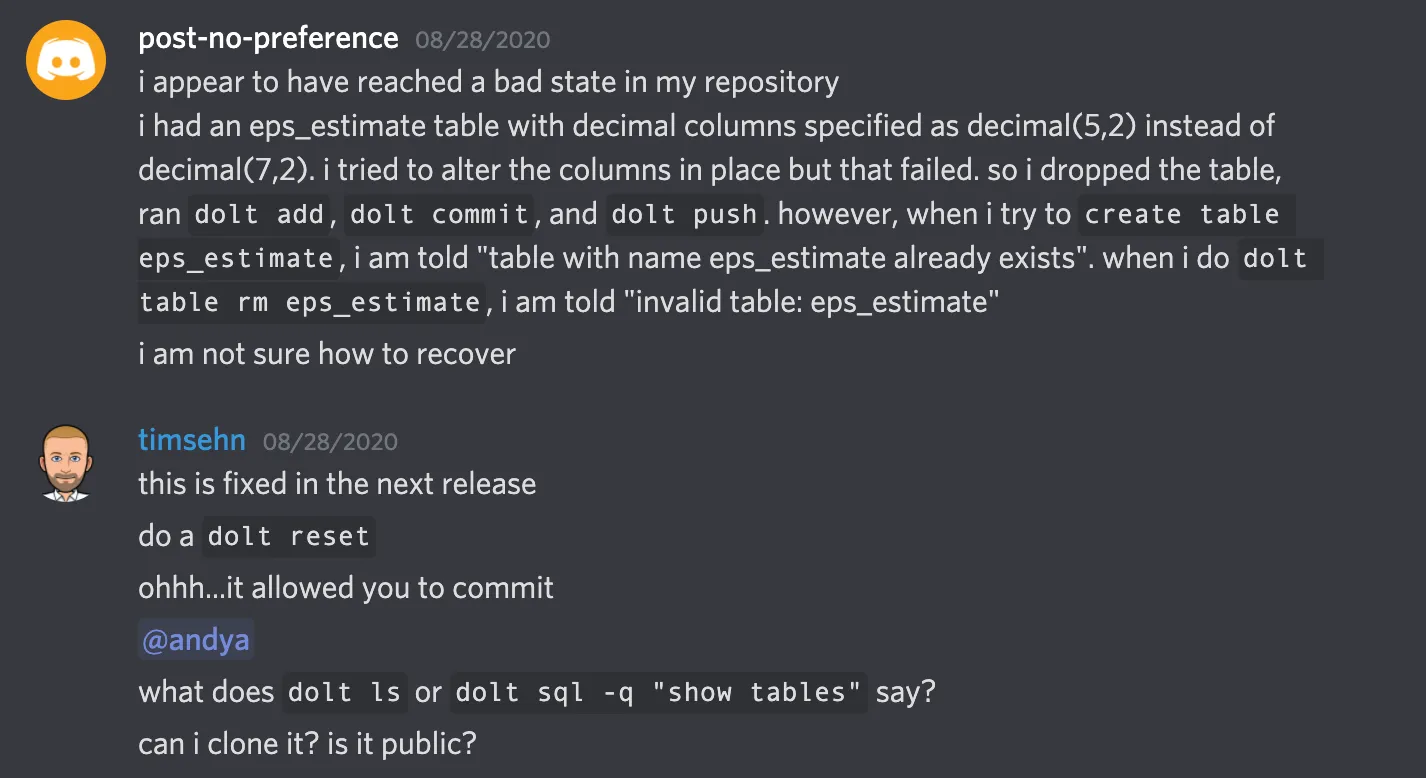
The key part of this exchange is the last part: “Can I clone it? Is it public?”. I can grab a copy of the database exactly as it exists for the user and start debugging. When you run into a problem using Dolt, you are not alone. Commit what you have and push the database to DoltHub. Hop on your favorite chat channel and ask for help. Anyone can see what you are seeing and start debugging without worrying about breaking anyone else.
Connecting to a shared database is just not the same because multiple people cannot make independent edits. Meanwhile, you have to worry about putting the database in a bad state for everyone. With Dolt, you are one dolt reset --hard away from erasing your mistakes.
So my exchange with post-no-preference goes on for a bit until I figure out what’s going on. At this point, I have something working. I don’t need to tell post-no-reference what I’ve done, I can just give him a working copy of the database. I commit and push my changes to his repository, assuming I have write permission.
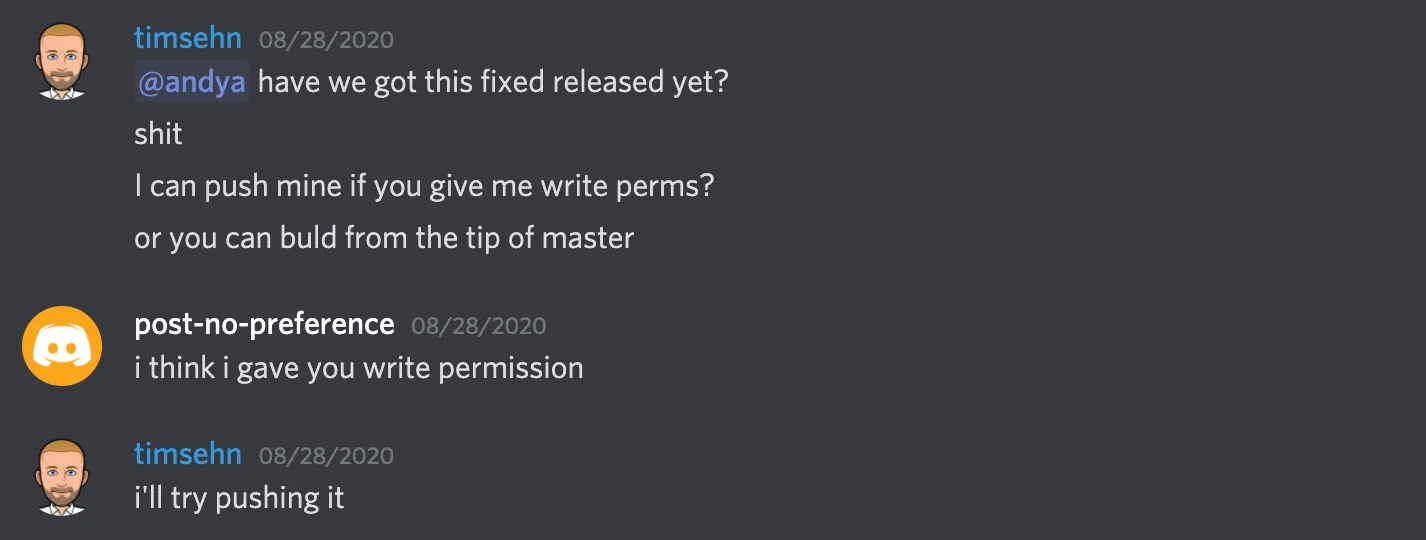
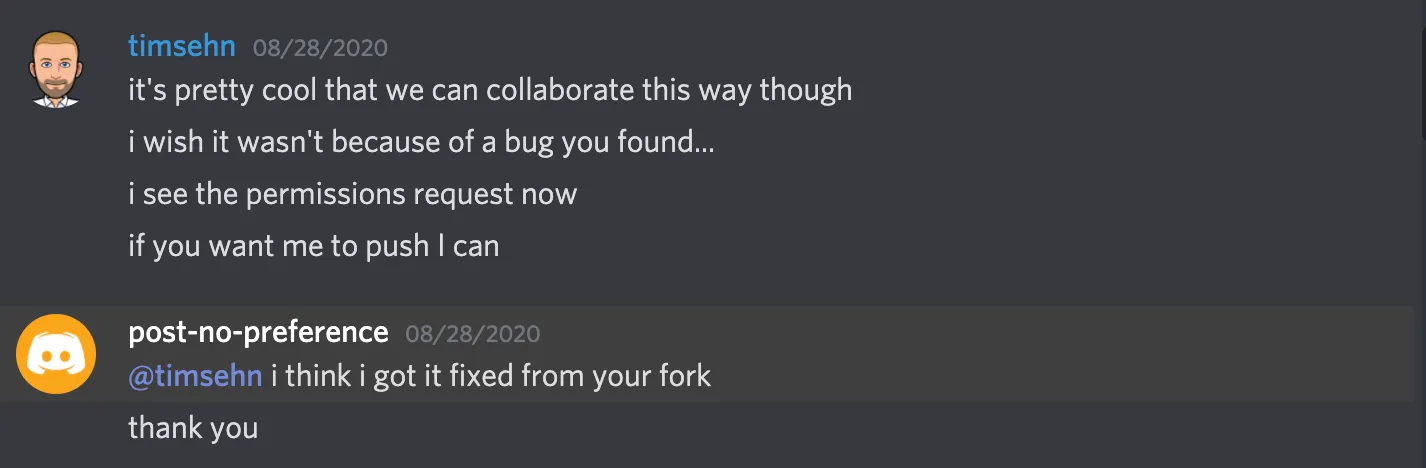
Before post-no-reference was able to give me permissions, I decided I did not want to stomp his copy so I made my own fork of the database in my own namespace and pushed to that. I thought that was more polite. Then, post-no-preference could clone a copy from my namespace and push it to his namespace if he so desired which is how it worked out.
Conclusion#
I think this example really shows off the distributed collaboration power of Dolt. post-no-preference and I were able to collaborate on his database in a safe way without ever having met in person. The Git and GitHub model of collaboration works for code and we think it can work for data as well. Give Dolt and DoltHub a try with some friends and see for yourself. We’ll be hanging out on our Discord if you have any questions.