
Dolt is a SQL database with Git-like functionality, including branch, merge and diff and push and pull to remotes. This is a post in a series of posts about the internal workings of some of the core algorithms that underly Dolt’s implementation. The previous posts in this series were about:
-
The Prolly-tree, a unique content-address indexed data structure that underlies Dolt’s table storage.
-
The Commit Graph and structural sharing in Dolt’s table storage.
In this post, we explore the Merkle DAG structure underlying Dolt’s commit graph and table storage a little more, and investigate how push and pull to remote repositories is implemented in Dolt.
Overview#
A Dolt repository contains any number of branches and tags, where each
branch or tag is a top-level reference to a particular commit. A
commit, in turn, points to a value of the database at that commit, and
0 or more parent commits. All data in the repository, the commits and
the table data, is stored in content-addressed Chunks which in turn
can contain references to other Chunks, forming a Merkle
DAG. This was the example
of a three commit branch from our previous blog post on the commit
graph:
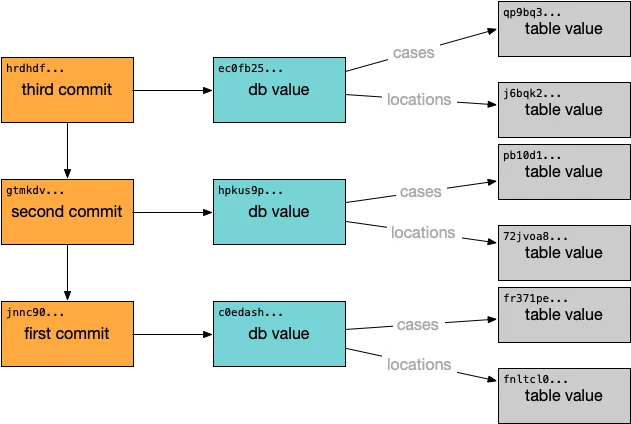
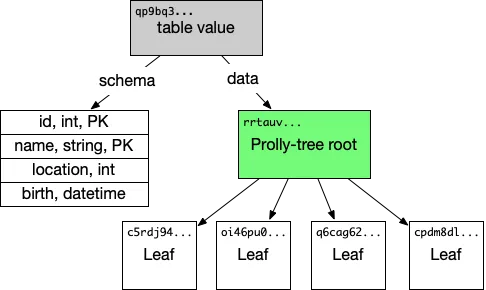
And this was the example of how the data in a single table might be broken down:
Dolt supports remotes, which means it can clone, push and pull branch and tag references from a Dolt repository stored in DoltHub or in cloud storage like AWS S3 or Google Cloud Storage. This blog post briefly explores what Dolt remotes are and how they operate under the hood.
A Dolt Remote#
A Dolt repository can have multiple remote repositories configured, and each of these repositories can be fetched from and pushed to separately. Each configured Dolt remote consists of three pieces of configuration within a Dolt repository:
-
The name of the remote. After a clone, this will be
origin. -
Configuration for a networked endpoint that implements a network protocol that Dolt can use as a remote. Most commonly, this is the GRPC API exported by https://doltremoteapi.dolthub.com and a DoltHub repository path like
dolthub/image-net. -
Default fetch specs for the remote. After a clone, this will be
refs/heads/*:refs/remotes/origin/*, and most users never need to interact directly with fetch specs.
The fetch spec is the subtlest piece of the configuration, but it’s
also fundamental to the way that remotes actually work. The above
fetch spec says: When we fetch from origin, create a new ref in
refs/remotes/origin/... for each ref we find in the remote at
refs/heads/.... refs/heads/... will be all the branches in the
remote, and so fetching from the remote will create corresponding refs
in our local repository for each branch in the remote repository. If
the remote had the branches main, bh/agi and aaron/by-zip, and
we fetched from it, Dolt would create the refs
refs/remotes/origin/main, refs/remotes/origin/bh/agi and
refs/remotes/origin/aaron/by-zip, each pointing at the corresponding
commits that the remote branches were pointing at when we ran the
fetch.
So the remotes refs namespace is separate from our local branches
namespace, and Dolt is keeping a copy of the branches that we fetch
from the remote locally. The only time that copy is updated, and the
only time we reference the remote generally, is when we run dolt fetch (or dolt pull, which does a fetch and then merge). And
the fundamental operation involved in a fetch is:
-
Contact the remote to list all the branches we will clone.
-
For each branch we will clone, update our local repository to contain the referenced Commit
Chunkand allChunks reachable from it. -
Set a corresponding
refin our local repository to point to the newly fetched CommitChunk.
Step #2 is where all the missing data actually gets copied into our local repository. Let’s take a look at exactly how that happens.
Chunk Stores and DAG Traversals#
As mentioned above, all the data in the repository, both Commits and
the table data, is stored in these content-addressed variable sized
blocks called Chunks. A storage abstraction exists in the Dolt
storage layer called a ChunkStore, which is a place where we can
read, and potentially write, chunks.
package chunk
type Address [20]byte
type Chunk interface {
// All of the chunk addresses that are referenced by this Chunk.
Refs() []Address
// The contents of the Chunk.
Bytes() []byte
}
type Store interface {
Has(addr Address) bool
Get(addr Address) Chunk
Put(contents Chunk)
}We can create a Store implementation for a remote repository which
is hosted in DoltHub, and we have a Store implementation for our
local repository as well. A simple recursive DAG walk to copy a given
commit (or any Chunk with all of its children) into our local
repository looks like:
func CopyChunks(to, from Store, a Address) {
if !to.Has(a) {
c := from.Get(a)
for _, r := range c.Refs() {
Fetch(to, from, r)
}
to.Put(c)
}
}This approach already has some nice properties. Ideally, if a Chunk
is in a Store, all the Chunks it references would also be in the
Store. We don’t want our algorithm to persist any Chunks to the
Store whose children we haven’t already fetched and persisted,
because if the algorithm gets aborted halfway through the Store
could then be in an inconsistent state. So we’re careful not to Put
the fetched Chunk until its children are persisted.
Better Performance With Batching#
In Go, the recursion is not much of a concern because goroutines have on-heap growable stacks. But if it is a concern, it’s easy to translate the call stack state into an explicit stack with on-heap state as well.
The above algorithm has one glaring issue: it’s very slow. If from
is a remote Store, then every Get is a round-trip RPC, and as
written there’s no capacity for pipelining or batching. The simplest
solution is to make the batching explicit. We can give Store batch
methods, and make CopyChunks take a slice of Addresses instead:
type Store interface {
// HasMany partitions the supplied addresses into ones that are
// already present in the `Store` and ones that are missing.
HasMany([]Address) (present, missing []Address)
// GetMany fetches all addresses from the store and returns the
// corresponding chunks in order.
GetMany([]Address) []Chunk
// PutMany persists the supplied chunks to the store.
PutMany([]Chunk)
}
func CopyChunks(to, from Store, as []Address) {
_, missing := to.HasMany(as)
chunks := from.GetMany(missing)
nextlevel := []Address{}
for _, c := range chunks {
nextlevel = append(nextlevel, c.Refs()...)
}
CopyChunks(to, from, nextlevel)
to.PutMany(chunks)
}That improves the round-trips for remote clones substantially and allows for better bandwidth utilization. But it introduces two new flaws.
-
Memory usage is potentially unwieldy. In the batched version, we’re holding a potentially large number of
Chunks in memory at every call toCopyChunks, and we’re making a call toGetManywith an unbounded number ofAddresses. Previously we were only holding oneChunkin memory at each level of the call. -
It potentially fetches the same
Chunks fromfrommultiple times. Two different length paths through the DAG to the sameChunkwill haveto.HasMany()returningmissingfor the sameChunkmultiple times, with consequent calls toGetMany()with the same addresses.
Addressing those actually gets somewhat complicated. In Dolt, for #1
we form explicit RPC batches and write the fetched Chunks to
temporary chunk files so that they don’t have to stay in memory. The
temporary files are constructed so that they can be cheaply integrated
into the to Store when all their dependencies are
persisted. Addressing #2 involves adding a little bit of book keeping
across recursive calls. But perfect behavior with regards to case #2
is actually a tradeoff between the batch sizes and memory usage. Once
the chunk from a higher level leaves memory and goes into the
temporary chunk file, it needs to be refetched from the remote or from
the disk in order to be incorporated in the to Store earlier than
its peers.
Fetch and Push#
It’s neat that the above algorithm works great whether operation is a
push or a fetch. If the remote Store is from, we’re doing a
fetch and we will get new chunks from the remote into our local
Store. But we can also make the remote Store to, in which case
its a push—the remote Store gets the new Chunks that were
unique to our local Store. In either case, once all the Chunks are
persisted in the to Store, we can update any refs appropriately,
setting them to point to the newly persisted commit Chunks based on
the operation we’re performing and the fetch/push specs as
appropriate.
Conclusion#
Dolt remotes are a powerful feature that allows for data
synchronization, collaboration and easily maintaining local changes
while tracking upstreams. Underlying the feature is a simple model for
how to build up the commit graph and the table data as a merkle DAG of
content addressed chunks. Building on top of that model allows for
push and fetch to be both be implemented by the same elegant DAG
walk. At the same time, practical engineering and performance concerns
introduce an opportunity for tradeoffs and optimization. Hopefully
we’ve given you some insight into the ways that Dolt approaches and
solves the issues underlying its implementation.