SQL Sync for Schema with SQL Alchemy

Dolt is a version controlled SQL database. It behaves like a traditional relational database in that it offers a SQL interface for data and schema management, but the underlying data structure is a commit graph inspired by Git. One natural use-case is to sync an existing database, such as Postgres or MySQL, to Dolt such that each commit in the Dolt commit graph represents the source database at a particular point in time. We can visualize this replication as follows:
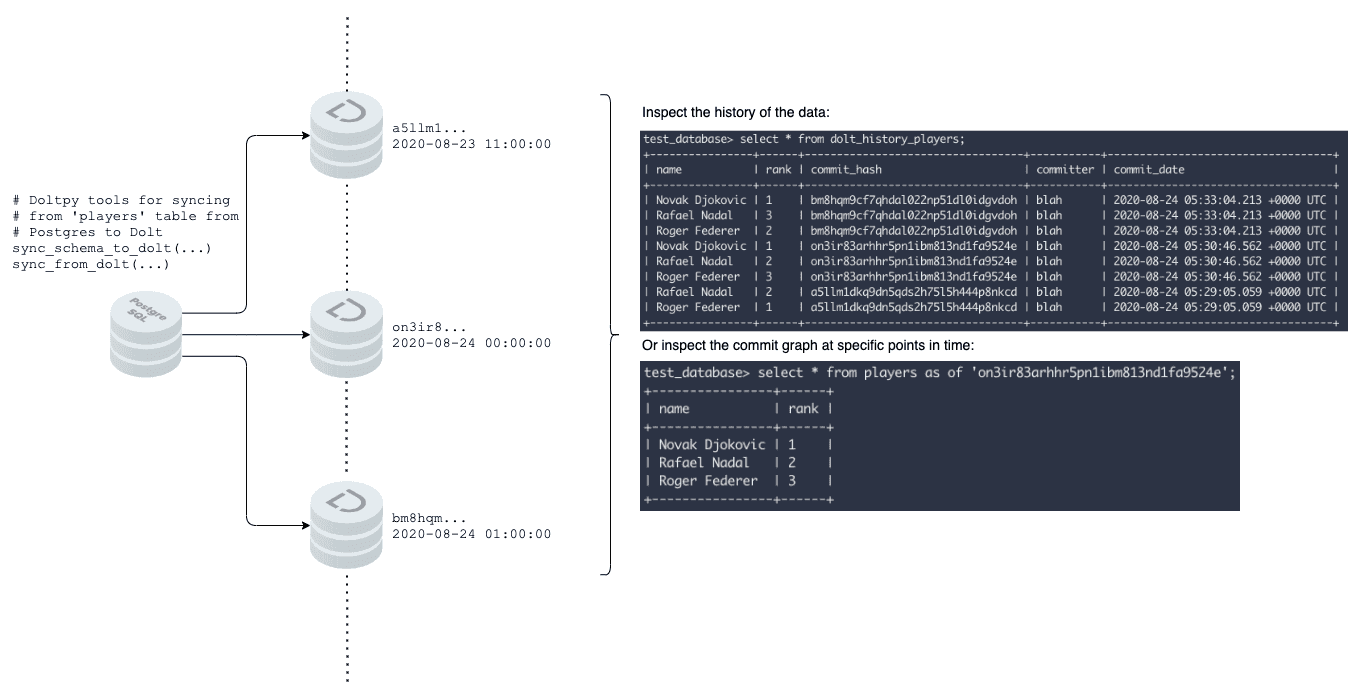
Once data from a production database instance is stored in a Dolt database, the Dolt SQL syntax for traversing the commit graph allows users to use AS OF syntax, as well as programmatic diffs, to understand how their data has changed through time without having to modify the production database. Each commit also acts as a database backup from which the production database can be restored.
In an earlier blogpost we introduced Python based tools for syncing data in MySQL to Dolt, and later Postgres, to Dolt. However, this still required users to manually recreate the schema from their source database instance, that is MySQL or Postgres, and recreate it in Dolt. We are excited to share new tooling in Doltpy that automates this schema translation.
Why
Before digging into an example, it's worth going over the motivations for doing this. While Doltpy makes this process straightforward, it's definitely more complicated than sharing a connection string with an analyst, data scientist, or anyone that may require access to the production database. We see the motivations as follows:
- Time travel: the first and most unique benefit is time travel, as illustrated in the diagram above. Dolt stores underlying data in a commit graph, and this commit graph will be updated on every sync, adding a temporal element to the data without altering the production schema. The full set of system tables for examining the commit graph can be found here.
- Experimentation: users can safely experiment with changes to the database that can be robustly examined using Dolt's diffing tools. These changes could be schema, or data, and are particularly useful for developing derived tables. We believe this is particularly valuable for data science teams that might be collaboratively building and managing datasets.
- Distribution: Dolt makes distribution to the team easy, each user can simply run
dolt cloneand immediately be setup with a MySQL server instance containing the production data in a safe data sandbox. Users can then run todolt pullto capture incremental updates as syncs push data and schema changes to the Dolt database. - Storage: Dolt efficiently computes deltas, so while every commit in the Dolt database represents the upstream database at a point in time, Dolt only stores the differences that appeared between the syncs.
In summary, we believe that Dolt presents a compelling way for teams to interact with their production data outside of the core application, and these new features in Doltpy lower the barrier to capturing that value.
We now move on to a concrete example of syncing a Postgres instance's schema and data to Dolt.
Example
Let's suppose that you have a Postgres instance from which you'd like to build a commit graph in the form of a Dolt database. You could even host the database on DoltHub. Dolt efficiently computes diffs between commits, storing only the data that has changed, thus this represents an efficient backup solution from a storage footprint standpoint. For simplicity we assume we have a single table named my_important_table, and we'd like to give it the same name in Dolt:
from doltpy.etl.sql_sync import sync_schema_to_dolt, POSTGRES_TO_DOLT_TYPE_MAPPINGS
from doltpy.core import Dolt
import sqlalchemy as sa
dolt = Dolt.init('path/to/dolt/db')
dolt.sql_server()
postgres_engine = sa.create_engine(
'{dialect}://{user}:{password}@{host}:{port}/{database}'.format(
dialect='postgresql',
user=postgres_user,
password=postgres_password,
host=postgres_host,
port=postgres_port,
database=postgres_database
)
)
table_map = {'my_important_table': 'my_important_table'}
sync_schema_to_dolt(postgres_engine, dolt, table_map, POSTGRES_TO_DOLT_TYPE_MAPPINGS)
dolt.add('my_important_table')
dolt.commit('Schema sync successful')This script will take your Postgres schema, map the types where appropriate using the SQL Alchemy abstraction and implementation specific packages, and then create the table on Dolt database server that we started using dolt.sql_server(). Let's use the existing tools to sync the data, reusing dolt to represent the Dolt database, and postgres_engine to tell doltpy how to use SQL Alchemy to interact with Postgres:
from doltpy.etl.sql_sync import sync_from_dolt, get_postgres_target_writer, get_dolt_source_reader
sync_from_dolt(get_dolt_source_reader(dolt, get_dolt_table_reader()),
get_postgres_target_writer(postgres_engine),
table_map)That's it! We've now created a repeatable script for transforming snapshotting your Postgres database, or a subset of its tables, into a Dolt database.
Using SQL Alchemy
We mentioned SQL Alchemy in the previous section. In a recent release, we migrated Doltpy to build on top of SQL Alchemy. SQL Alchemy is a "Python SQL toolkit" that provides an elegant SQL abstraction toolkit across SQL implementations. In our initial implementation of data sync, we had used raw SQL to express moving data to and from Dolt and Postgres or MySQL. This led to lots of conditional rendering of raw SQL queries, which was buggy and hard to work with. SQL Alchemy's full featured toolkit for abstracting across databases allowed us to express the necessary schema and data transformation code in Python, and thus avoid conditional manipulation raw SQL. As an example, the only database specific code that had to be added to our Postgres specific code was the following mapping:
from sqlalchemy.dialects import mysql, postgresql
POSTGRES_TO_DOLT_MAPPINGS = {
postgresql.CIDR: mysql.VARCHAR(43),
postgresql.INET: mysql.VARCHAR(43),
postgresql.MACADDR: mysql.VARCHAR(43),
postgresql.JSON: mysql.LONGTEXT,
postgresql.JSONB: mysql.LONGTEXT,
postgresql.ARRAY: mysql.LONGTEXT,
postgresql.UUID: mysql.VARCHAR(43),
postgresql.BYTEA: mysql.LONGTEXT
}Mapping a schema is then straight forward, and takes place in pure Python:
def coerce_schema_to_dolt(target_table_name: str,
table: Table,
type_mapping: dict) -> Table:
target_cols = []
for col in table.columns:
target_col = coerce_column_to_dolt(col, type_mapping)
target_cols.append(target_col)
# TODO:
# currently we do not support table or column level constraints except for nullability. We simply ignore these.
return Table(target_table_name, MetaData(), *target_cols)
def coerce_column_to_dolt(column: Column, type_mapping: dict):
"""
Defines how we map MySQL types to Dolt types, and removes unsupported column level constraints. Eventually this
function should be trivial since we aim to faithfully support MySQL.
:param column:
:param type_mapping:
:return:
"""
return Column(column.name,
type_mapping[type(column.type)] if type(column.type) in type_mapping else column.type,
primary_key=column.primary_key,
autoincrement=column.autoincrement,
nullable=column.nullable)In summary SQL Alchemy allows us to write generic Python code against an abstraction of underlying database implementations, but then exposes implementation specific details, such as the nuances of various types, and allows us to delegate appropriately.
Conclusion
Doltpy, building on top of Dolt and SQL Alchemy, make it easy to replicate existing databases in a commit graph like structure. The motivation for doing so could be data backups of production databases, or developing richer understanding of point in time data, or simply seeing diffs through time that an existing database does not make available.