
Dolt is Git for data and DoltHub hosts a growing collection of public open datasets. Recently, we created dolthub/fbi-nibrs reflecting the FBI’s National Incident Based Reporting System (NIBRS) crime data. Law enforcement agencies from around the United States voluntarily report their crime data to the FBI using the NIBRS and the FBI distributes this crime data by state and year.
Unlike the FBI’s distribution of this crime data however, we set out to make dolthub/fbi-nibrs a comprehensive stand alone dataset that includes all states that participated from 1991 to 2018. dolthub/fbi-nibrs currently contains crime data for about 25 states and we are adding more everyday.
One reason we are particularly excited about this dataset is because we think it highlights some serious problems facing modern data consumers, or people who want to acquire and use open datasets. Our intention is to identify the common problems facing data consumers and present the ways we think Dolt specifically solves them for the benefit of everyone. Below, we contrast the current publishing format of the FBI NIBRS crime data (the comma separated value file or CSV) with its new (and we think better) Dolt format.
The Current Format of Data Distribution#
As mentioned above, the FBI distributes its NIBRS data in bulk as a collection of CSV files available for download by state and by year. These files are contained within a zipped directory, and are packaged with very comprehensive README files and SQL files for easily loading the CSVs into sqlite or PostgreSQL, sometimes both.
$ ls fbi-nibrs-data/michigan
1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018
$ ls fbi-nibrs-data/michigan/1995
README.html nibrs_bias_list.csv nibrs_injury.csv nibrs_property_desc.csv nibrs_victim_offense.csv
README.md nibrs_bias_motivation.csv nibrs_justifiable_force.csv nibrs_relationship.csv nibrs_victim_type.csv
agency_participation.csv nibrs_circumstances.csv nibrs_location_type.csv nibrs_suspect_using.csv nibrs_weapon.csv
cde_agencies.csv nibrs_cleared_except.csv nibrs_month.csv nibrs_suspected_drug.csv nibrs_weapon_type.csv
nibrs_activity_type.csv nibrs_criminal_act.csv nibrs_offender.csv nibrs_suspected_drug_type.csv postgres_load.sql
nibrs_age.csv nibrs_criminal_act_type.csv nibrs_offense.csv nibrs_using_list.csv postgres_setup.sql
nibrs_arrest_type.csv nibrs_diagram.pdf nibrs_offense_type.csv nibrs_victim.csv ref_race.csv
nibrs_arrestee.csv nibrs_drug_measure_type.csv nibrs_prop_desc_type.csv nibrs_victim_circumstances.csv ref_state.csv
nibrs_arrestee_weapon.csv nibrs_ethnicity.csv nibrs_prop_loss_type.csv nibrs_victim_injury.csv sqlite_load.sql
nibrs_assignment_type.csv nibrs_incident.csv nibrs_property.csv nibrs_victim_offender_rel.csv sqlite_setup.sqlWhat’s nice about this type of data distribution is it actually does make it relatively easy and straightforward for consumers to get up and running querying the data for the given state and year that they selected. The README details what the consumer can expect from the collection of CSV files and the consumer then only needs to be familiar enough with one of those SQL databases to be able to pipe in the the provided “setup” .sql file followed by the “load” .sql file and then data becomes queryable.
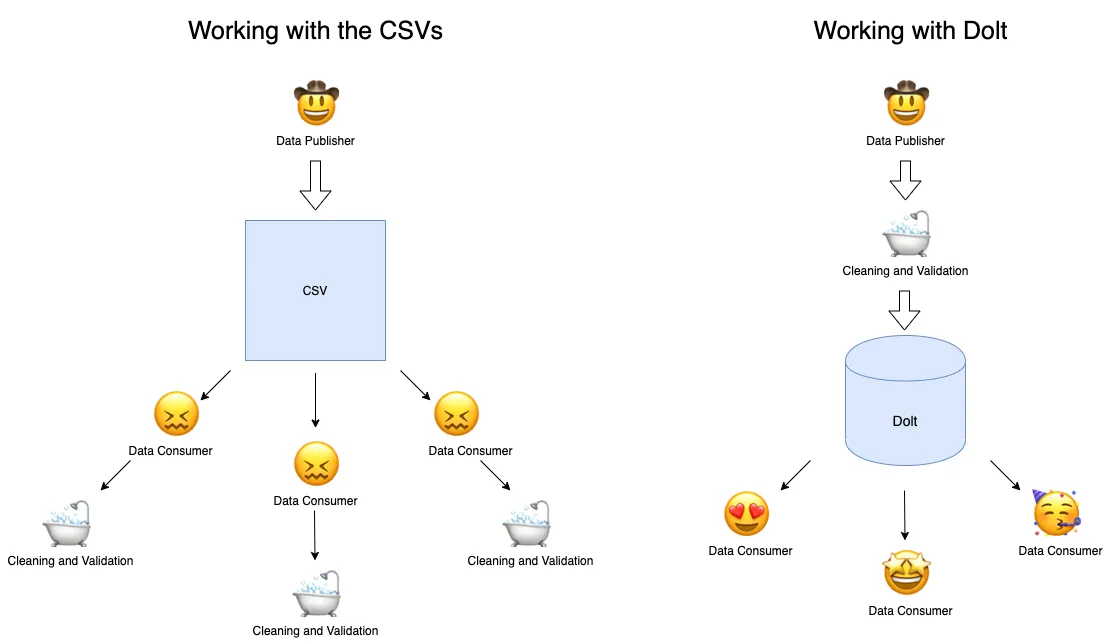
As far as the current popular form of data distribution, this is actually really good. Shipping CSVs alongside SQL files and documentation is about as comprehensive a data package as you can find in the open data world. However, even with this comprehensive assortment of materials there are inherent drawbacks to distributing data via CSVs.
One such drawback is that the CSV file alone is never enough. As evidenced by the FBI’s bulk data zip directory, raw CSV files despite containing the actual data, need accompanying materials packaged with them simply because the CSV file isn’t very useful except for holding data. No data consumer can query the CSV to find out about the data, let alone any relationships within the data. And no consumer is going to try reading data row by row in a CSV file. For that reason, it’s much more useful to package raw CSV files with something like a SQL file, just like the FBI does, which requires a small amount of effort to turn an un-queryable CSV into a queryable database instance.
Another drawback to this form of data distribution arises when considering what this process looks like if a consumer, us in this example, wants the data for all states between the years 1991 and 2018. Each state and year combination requires a download of 43 CSV files per state, per year, which then must be loaded into a database in order to query. Even after loading data for a given state/year, the scope of the crime data is limited; queries for a state across all years are not possible, and queries for a year across all states are not possible. It would take a large amount of work to translate this collection of state/year crime datasets into a single, comprehensive dataset that allowed for more robust queries of a wider scope (which we have done!).
That said, this is the first example of how Dolt beats the CSV. Now that dolthub/fbi-nibrs exists, a consumer wanting crime data does not need to download any CSV files, any SQL files, and doesn’t need to download data by state and by year. The beauty of Dolt formatted data is that the data and SQL are one. There are no CSV files because in Dolt, the data already lives in tables. There are no SQL files because Dolt is a SQL database, meaning you can begin querying the data immediately. There are no zip folders to unzip and since the Dolt repository is publicly available on DoltHub, it can be cloned with a single command by anyone $ dolt clone dolthub/fbi-nibrs. Our goal in building Dolt from the ground up as a versioned, scalable data distribution format was to make finding, sharing, and working with data so much more pleasant for data consumers.
$ dolt clone dolthub/fbi-nibrs
cloning https://doltremoteapi.dolthub.com/dolthub/fbi-nibrs
18,283,374 of 18,283,374 chunks complete. 0 chunks being downloaded currently.
$ cd fbi-nibrs/
$ dolt sql -q 'show tables;'
+----------------------------+
| Table |
+----------------------------+
| agency_participation |
| agency_table_type |
| cde_agencies |
| nibrs_activity_type |
| nibrs_age |
| nibrs_arrest_type |
| nibrs_arrestee |
| nibrs_arrestee_weapon |
| nibrs_assignment_type |
| nibrs_bias_list |
| nibrs_bias_motivation |
| nibrs_circumstances |
| nibrs_cleared_except |
| nibrs_criminal_act |
| nibrs_criminal_act_type |
| nibrs_drug_measure_type |
| nibrs_ethnicity |
| nibrs_incident |
| nibrs_injury |
| nibrs_justifiable_force |
| nibrs_location_type |
| nibrs_month |
| nibrs_offender |
| nibrs_offense |
| nibrs_offense_type |
| nibrs_prop_desc_type |
| nibrs_prop_loss_type |
| nibrs_property |
| nibrs_property_desc |
| nibrs_relationship |
| nibrs_suspect_using |
| nibrs_suspected_drug |
| nibrs_suspected_drug_type |
| nibrs_using_list |
| nibrs_victim |
| nibrs_victim_circumstances |
| nibrs_victim_injury |
| nibrs_victim_offender_rel |
| nibrs_victim_offense |
| nibrs_victim_type |
| nibrs_weapon |
| nibrs_weapon_type |
| ref_race |
| ref_state |
+----------------------------+Aggregating States and Years#
As mentioned above, we’ve already done the work of aggregating the FBI’s crime data into a single database so that consumers can write more robust queries against it. A very interesting aspect of the crime data I discovered while working on this dataset was discovering the data’s history.
Like all data, the FBI’s NIBRS data has changed and will undoubtedly continue to change. Its schema has changed, the data values and definitions have changed, and if you’re trying to accurately represent the FBI’s crime data, you have to represent the data’s history, not just a single “state” of the data.
Here is specifically what I mean. The FBI’s NIBRS crime data used one version of the schema from 1991 to 2015. From 2016 onward, it started using a second version of the schema. The differences in schema versions it uses involve the replacement of a table cde_agencies with the updated agencies table, the removal of a table called agency_participation and some added and dropped columns throughout the various tables. In fact, see the differences for yourself right on DoltHub!
In addition, some important data values changed when the old schema, or legacy schema, was migrated to the modern one. For instance in the reference tables published prior to 2016 we can see the addition of a little known US state called Testy McTesterstate, a pretty funny discovery we found when poking around the crime data.
We can also see changes in official terminology. For example, “Lovers Quarrel”, defined as an official “Circumstance” from 1991 to 2015 became “Domestic Violence” in 2016. These simple examples, though maybe not immediately significant to a data consumer, demonstrate a reality of data. It changes. Things change, people change, data changes. And we need a data format that can represent its changes in order to represent the data accurately.
It’s not sufficient to represent aggregated crime data in SQL databases that do not support versions of the data. Doing so pretends that the data exists in a single, fixed state but that’s not how this data, or any data actually exists. We believe the data format of the future should accept this truth, not neglect it.
This is why we built Dolt to version data and track changes in the same way Git does for files. Without Dolt, representing the aggregated crime data in a single database instance ignores the data’s past and makes it difficult to change in the future. Old data values, columns, and tables are lost forever as if they’d never existed. New data values, columns, and tables become problematic to add; maybe they overwrite some existing value, or require some fundamental change to the underlying schema.
The Dolt data format enables data consumers to get the entire history of data in a single repository, all at once. If you want to see the data and schema the FBI used for years 1991 to 2015, you simply checkout the master branch and start querying.
fbi-nibrs$ dolt checkout master
Switched to branch 'master'
fbi-nibrs$ dolt sql -q 'describe nibrs_offense;'
+-----------------------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------------+----------+------+-----+---------+-------+
| STATE_ID | smallint | NO | PRI | | |
| DATA_YEAR | int | NO | PRI | | |
| OFFENSE_ID | bigint | NO | PRI | | |
| INCIDENT_ID | bigint | NO | MUL | | |
| OFFENSE_TYPE_ID | bigint | NO | MUL | | |
| ATTEMPT_COMPLETE_FLAG | char(1) | YES | | | |
| LOCATION_ID | bigint | NO | MUL | | |
| NUM_PREMISES_ENTERED | smallint | YES | | | |
| METHOD_ENTRY_CODE | char(1) | YES | | | |
| FF_LINE_NUMBER | bigint | YES | | | |
+-----------------------+----------+------+-----+---------+-------+If you want the data in its current or latest version, from 2016 onward, you checkout the latest branch and start querying.
fbi-nibrs$ dolt checkout latest
Switched to branch 'latest'
fbi-nibrs$ dolt sql -q 'describe nibrs_offense;'
+-----------------------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------------------+----------+------+-----+---------+-------+
| STATE_ID | smallint | NO | PRI | | |
| DATA_YEAR | int | NO | PRI | | |
| OFFENSE_ID | bigint | NO | PRI | | |
| INCIDENT_ID | bigint | NO | MUL | | |
| OFFENSE_TYPE_ID | bigint | NO | MUL | | |
| ATTEMPT_COMPLETE_FLAG | char(1) | YES | | | |
| LOCATION_ID | bigint | NO | MUL | | |
| NUM_PREMISES_ENTERED | smallint | YES | | | |
| METHOD_ENTRY_CODE | char(1) | YES | | | |
+-----------------------+----------+------+-----+---------+-------+With Dolt, we don’t need to pretend that the data hasn’t changed or won’t change again, we embrace it. Anyone wanting this aggregated crime data now gets its full history, and the promise of it’s full future, in a type-safe, queryable format.
Data Expectation vs Reality#
Lastly, anyone with experience working with data in CSV form knows that the actual data within it too often doesn’t match the descriptions about the data, if the data has descriptions about it at all. Maybe the data doesn’t conform to the exact schema we expected it to follow. Maybe the data has incorrect data types for a given column.
This is why cleaning and validating raw data is such an important and time consuming part of traditional data science and analysis.
Even within the CSVs published by the FBI, we found discrepancies that only function to make consuming data a pain in the ass. Some issues we encountered were as simple as broken foreign key constraints or incorrectly renamed column headers that were not actually reflected in the schema. We even found CSVs containing invisible non utf-8 encoded characters that prevented programmatically opening the files. And as far as the FBI and other data publishers are concerned, maybe they shouldn’t care about the materials they distribute or the quality of the raw data. Maybe the burden of data cleaning and validating rests solely on the consumer side. But we want to change that. And if not us, someone should change that so we can start sharing clean data with each other!
Data discrepancies are pervasive in CSV formatted data because the CSV file is not type-safe, it’s just raw text. With a type-safe format, where the work of data cleaning and validation has been performed on the data publishing side, consumers start with high quality data out-of-the-box and can immediately begin querying that data. We fundamentally believe that the current model of distributed data, where each consumer must clean and validate all of the CSVs they intend to use is flawed. There is no reason this work needs to be repeated more than once.
We hope that dolthub/fbi-nibrs is a shining example of this new paradigm. The data was cleaned and validated once, by us, and is now available in Dolt, our type-safe versioned format. All of the problems we encountered while working with the FBI’s raw CSVs, we’ve solved, and no consumer needs to duplicate that work in order to get or query the data. Broken data relationships can be identified with a single query, every data value matches the exact column data type, and all characters are correctly encoded.
This is what we mean when we talk about open data. Like open source software, the work that goes into creating software is shared freely, enabling others to not have to duplicate work arbitrarily. This ground-breaking paradigm enabled the boom of modern software development and we believe it will enable a boom in data. With Dolt, work on data is performed once, then shared, enabling data consumers to avoid non-trivial distractions and just start querying.
On to the Data!#
We are really excited about this dataset and we hope you find it interesting! This blog won’t go into too much detail about the dataset itself, it’s construction and contents are well documented here. I have, however, included some examples of how dolthub/fbi-nibrs enables some interesting wider scoped queries that were previously not possible.
For example, with the aggregated dataset we can now see the number of incidents reported in 2012 across all available states:
fbi-nibrs$ dolt sql -q 'select ni.STATE_ID, rs.STATE_NAME, ni.DATA_YEAR, count(ni.DATA_YEAR) as INCIDENTS_PER_YEAR from nibrs_incident ni join ref_state rs on ni.STATE_ID = rs.STATE_ID where ni.DATA_YEAR=2012 group by ni.STATE_ID, rs.STATE_NAME ORDER BY ni.STATE_ID, rs.STATE_NAME;
'
+----------+----------------------+-----------+--------------------+
| STATE_ID | STATE_NAME | DATA_YEAR | INCIDENTS_PER_YEAR |
+----------+----------------------+-----------+--------------------+
| 2 | Alabama | 2012 | 4035 |
| 5 | Arizona | 2012 | 12623 |
| 10 | District of Columbia | 2012 | 3061 |
| 11 | Delaware | 2012 | 68668 |
| 18 | Illinois | 2012 | 16777 |
| 22 | Louisiana | 2012 | 36868 |
| 25 | Maine | 2012 | 17236 |
| 28 | Missouri | 2012 | 64725 |
| 30 | Montana | 2012 | 50114 |
| 31 | Nebraska | 2012 | 29964 |
| 33 | North Dakota | 2012 | 32857 |
| 34 | New Hampshire | 2012 | 66029 |
| 40 | Oklahoma | 2012 | 50839 |
| 42 | Pennsylvania | 2012 | 9 |
| 44 | Rhode Island | 2012 | 54486 |
| 46 | South Dakota | 2012 | 35812 |
| 52 | Vermont | 2012 | 28148 |
| 55 | West Virginia | 2012 | 84254 |
+----------+----------------------+-----------+--------------------+We can also hone in on a particular state across years. Let’s peek at Pennsylvania’s reported incidents:
$ dolt sql -q 'select ni.STATE_ID, rs.STATE_NAME, ni.DATA_YEAR, count(ni.DATA_YEAR) as INCIDENTS_PER_YEAR from nibrs_incident ni join ref_state rs on ni.STATE_ID = rs.STATE_ID where ni.STATE_ID = 42 group by ni.DATA_YEAR ORDER BY ni.DATA_YEAR;
'
+----------+--------------+-----------+--------------------+
| STATE_ID | STATE_NAME | DATA_YEAR | INCIDENTS_PER_YEAR |
+----------+--------------+-----------+--------------------+
| 42 | Pennsylvania | 2012 | 9 |
| 42 | Pennsylvania | 2013 | 943 |
| 42 | Pennsylvania | 2014 | 4795 |
| 42 | Pennsylvania | 2015 | 5880 |
| 42 | Pennsylvania | 2016 | 5265 |
| 42 | Pennsylvania | 2017 | 5421 |
| 42 | Pennsylvania | 2018 | 3691 |
+----------+--------------+-----------+--------------------+Lastly, let’s get a breakdown the types of offenses Pennsylvania reported in 2013 (NOTE: some “Incidents” map to multiple “Offenses”):
$ dolt sql -q 'select ot.OFFENSE_NAME, count(*) as OFFENSE_COUNT from nibrs_offense o join nibrs_offense_type ot on o.OFFENSE_TYPE_ID = ot.OFFENSE_TYPE_ID where STATE_ID=42 and DATA_YEAR=2013 group by ot.OFFENSE_NAME order by OFFENSE_COUNT desc;'
+---------------------------------------------+---------------+
| OFFENSE_NAME | OFFENSE_COUNT |
+---------------------------------------------+---------------+
| All Other Larceny | 155 |
| Simple Assault | 144 |
| Destruction/Damage/Vandalism of Property | 116 |
| Shoplifting | 97 |
| Burglary/Breaking & Entering | 92 |
| Drug/Narcotic Violations | 83 |
| Drug Equipment Violations | 72 |
| Theft From Building | 64 |
| Theft From Motor Vehicle | 58 |
| Credit Card/Automated Teller Machine Fraud | 38 |
| False Pretenses/Swindle/Confidence Game | 36 |
| Stolen Property Offenses | 18 |
| Intimidation | 15 |
| Counterfeiting/Forgery | 15 |
| Impersonation | 15 |
| Motor Vehicle Theft | 12 |
| Weapon Law Violations | 12 |
| Robbery | 6 |
| Sodomy | 6 |
| Sexual Assault With An Object | 5 |
| Theft of Motor Vehicle Parts or Accessories | 5 |
| Pornography/Obscene Material | 4 |
| Murder and Nonnegligent Manslaughter | 4 |
| Aggravated Assault | 4 |
| Fondling | 4 |
| Embezzlement | 4 |
| Rape | 3 |
| Statutory Rape | 2 |
| Arson | 2 |
| Prostitution | 1 |
| Pocket-picking | 1 |
| Kidnapping/Abduction | 1 |
+---------------------------------------------+---------------+Conclusion#
If you found this interesting and useful, and I encourage you to clone your own copy of this dataset and star the repo on DoltHub to let us know you checked it out!
Curious about Dolt, DoltHub and the versioned data format of the future? There’s no better place to get started than DoltHub.com where you can download Dolt, host your own public and private repositories, or just clone some amazing public repositories you won’t find anywhere else.
Questions, comments, or looking to start publishing your data in Dolt? Get in touch with our team here!