How DoltHub Integrates Metered Billing with Stripe

Dolt is a SQL database with Git-style versioning. DoltHub is a place on the internet to share Dolt databases. Dolt is and always will be an open source tool and DoltHub hosts all public repositories for free.
Users interested in hosting private repositories on DoltHub can subscribe to DoltHub's Pro plan for $50/month, which includes up to 100GB/month of free private storage, where each additional GB/month costs only 10 cents. This plan allows for unlimited seats in your organization so bring as many collaborators as you like!
Stripe is a robust and flexible software platform that builds streamlined, reliable tools for internet commerce. When developing DoltHub, we chose to use Stripe for DoltHub's billing and payment service because of its high quality developer API as well as it's clear and comprehensive documentation. I'll never forget the excitement of one team member exclaiming "have you seen the Stripe docs? They're fucking amazing!"
For DoltHub's purposes, we were particularly interested in Stripe's Subscription model for implementing our DoltHub Pro subscription plan. To create the Pro subscription plan, we used two of Stripe's Subscription features -- a recurring, Fixed-price monthly subscription plan that bills DoltHub Pro subscribers the base monthly price of $50, and a second Subscription feature Stripe refers to as it's Metered Billing.
The metered billing plan simply means that we expect usage from subscriber to subscriber to vary, so Stripe allows us to report the amount of storage each DoltHub Pro subscriber has consumed during a given month. Stripe then bills that subscriber, on our behalf, for the amount we've reported.
Stripe really does make setting up and managing billing and subscription services easy. We thought some readers might enjoy an overview of how we implemented a custom metering pipeline designed to measure and report DoltHub Pro subscriber's monthly metered repository storage.
DoltHub's Metering Pipeline
DoltHub's metering pipeline consists of a number of different jobs and services. These jobs and services perform the following functions:
- Aggregate repository metadata
- Assemble repository timelines
- Report repository consumption to Stripe
- Monitor the metering pipeline
Repository metadata aggregation
DoltHub's metering pipeline starts here. In order to accurately represent the state of each repository on DoltHub, we employ some scheduled jobs that work to provide the inputs for the subsequent phases of the pipeline. The key inputs aggregated during this initial phase are repository snapshots, CloudTrail events, and DoltHub events.
Repository snapshots form the backbone of how DoltHub determines a repository's size for billing purposes. Repository data hosted on DoltHub is stored in chunks in AWS S3 and we use two daily scheduled jobs to snapshot a repository's size. The first job organizes our S3 chunk store into chunk buckets partitioned by repository, and the second job parses chunk data, then determines and records a repository's total size. This forms a repository snapshot. These snapshots provide a momentary glimpse of a repository's state, but they alone are not enough to accurately represent a repository's changing state over time.
To get the full representation of a repository's state and how it's changed, we combine these snapshots with two other important inputs -- CloudTrail events and DoltHub events.
AWS CloudTrail is a managed logging service which we use for DoltHub's S3 chunk bucket. Whenever DoltHub users add, remove, or modify data in their repositories, events are fired and logged in CloudTrail for later retrieval. As part of our metering pipeline, we've created another scheduled job that extracts these logged events and aggregates them by repository within a given time frame. These events, which are time-stamped, helps us form a more clear picture of when and how repository data has changed.
Similarly, when users change the visibility of a repository on DoltHub, DoltHub itself fires its own events which are stored and later aggregated, to be combined with the CloudTrail events and repository snapshots. The combination of these three inputs are what we call repository "timelines". A repository timeline is essentially a representation of each repository's changing state over a period of time. DoltHub uses these timelines to determine how much storage DoltHub Pro subscribers consume and, thus, what to report to Stripe under its Metered Billing model.
Repository timeline assembly
The above processes create three crucial inputs that are assembled to form a high-resolution timeline representing the amount of storage a given repository consumes over time. The next phase of our metering pipeline, the assembly phase, employs a job that merges and orders events and snapshots from the jobs above, resulting in a timeline. For example, take the following inputs for a single repository:
Snapshots
Time: June 1st 7am, Total Size: 2GB, Visibility: Public
Time: June 2nd 7am, Total Size: 4GB, Visibility: Private
CloudTrail Events
Time: June 1st 5am, Event: Put Object, Size: 2GB
Time: June 1st 12pm, Event: Put Object, Size: 2GB
DoltHub Events
Time: June 1st 2pm, Event: Update Visibility, Visibility: Private
Our job would assemble a timeline that looks like this:
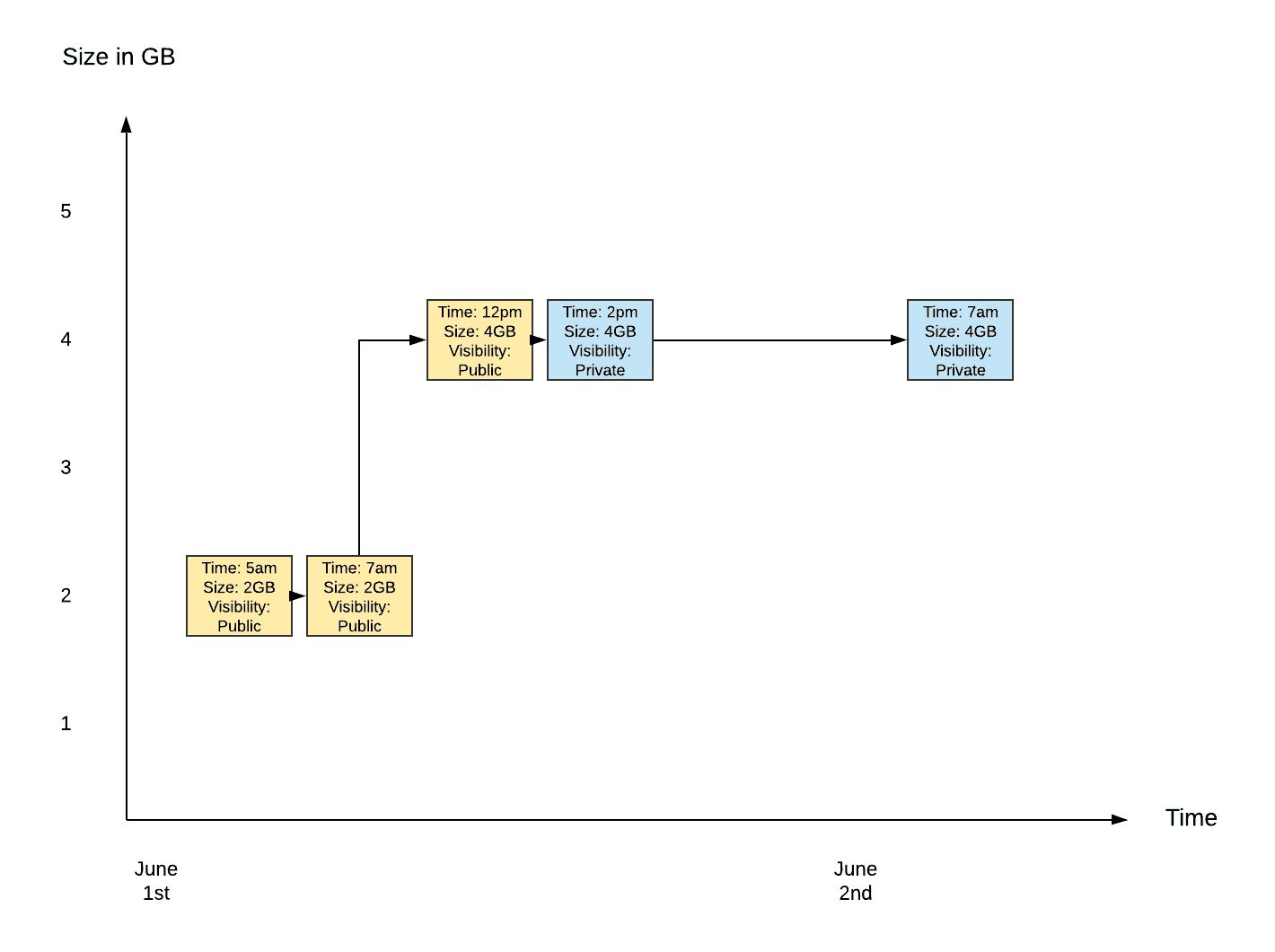
As you can see from the above example, the assembled timeline contains all the events that took place, correctly ordered, which reflects the changing state of the example repository from June 1st to June 2nd.
This assembly process gives us an accurate representation of each repository's changing state, and crucially, the duration of time the repository remained in each state. For a given DoltHub Pro subscriber, having this information for every repository they own gives us exactly the information we need to report their monthly metered usage to Stripe.
Reporting repository consumption to Stripe
The reporting phase of our metering pipeline employs a single job, but runs in two different ways, at two distinct times. The first way, which we consider the "default" way, runs daily. Its purpose is to post Usage Records to Stripe reflecting a subscriber's total private repository GBs consumed during the subscriber's current billing period. This daily run will always post the most current total for each subscriber and its daily scheduling and posting means that Stripe has close-to-current data for every subscriber.
The second way we run the job is on demand, in order to report to Stripe the final utilization for a customer's invoice which is about to be billed. We kick off the job to report for a single subscriber from a server which processes Stripe webhook requests.
Webhooks are another great feature of Stripe and they enable clients to respond to various asynchronous billing and payment events in an incredibly straightforward way. These events include things like payment successes, payment failures, and various subscription updates.
In our Stripe webhooks server, as part of invoicing a DoltHub Pro subscriber, we do a final run of the reporting job for the invoiced period whenever we get an invoice.created event from Stripe. invoice.created events are emitted before an invoice is finalized and a subscriber is billed. We call this on demand run the final "true-up" run.
True-up here simply means we want to calculate a subscriber's total repository usage one final time and report that to Stripe to "true up" or make sure Stripe has the most accurate information, before the subscriber's invoice is finalized and the subscriber is officially billed.
Monitoring the metering pipeline
As you can see we use a number of jobs and services in our metering pipeline that depend on one another to successfully bill each of our Pro subscribers. To ensure our pipeline is highly reliable we've also added a monitoring service that watches the various jobs and services in our metering pipeline and alerts our admins if any part of the pipeline unexpectedly fails.
Since our metering pipeline is built atop Kubernetes, we've leveraged its API in our monitoring service to watch jobs in the pipeline with a "monitor" Label. Any job or service in the pipeline deployed with this label sends notifications to our admins upon failure.
This monitoring service also adds a custom Annotation to the failed jobs and services indicating whether admins have already been alerted for this failure and the time an alert was sent. We then leave these jobs dangling in our Cluster for inspection. Jobs and services that have succeeded are removed.
Though relatively simple in its current state, this monitoring service is crucial in ensuring the orchestration of our metering pipeline runs as expected, or alerts us if it does not.
Conclusion
We hope you've enjoyed this brief overview of how we've integrated DoltHub with Stripe and specifically how we've taken advantage of Stripe's Metered Billing Subscription model. We've found Stripe's API, documentation, and commitment to the developer experience to be truly great. We're happy we selected Stripe as our metered billing provider.
We had plenty to do ourselves when implementing our metering pipeline so we've really appreciated Stripe's great work, making payment integration and management such a cinch.
Curious about Dolt, DoltHub and the versioned data format of the future? There's no better place to get started than Dolthub.com where you can download Dolt, host your own public and private repositories, or just clone some amazing public repositories you won't find anywhere else, including some interesting and up-to-date COVID-19 data.
Questions, comments, or looking to start publishing your data in Dolt? Get in touch with our team here!