
Dolt is a SQL database with Git-style versioning. DoltHub is a place to share Dolt repositories. Dolt is Git for data. DoltHub is GitHub for Dolt. We want to host your public data on DoltHub. We think Dolt and DoltHub provide the best sharing model and interfaces to open data. We will host your open data project on DoltHub for free.
In an earlier blog post, we showed you you how to publish data using SQL. In this blog post, we’ll show you how to publish data from Comma Separated Value (CSV) files. CSVs are very popular for sharing data today. It’s easy to convert one or many CSV files into a Dolt database.
Step 1: Create a DoltHub account#
Go to DoltHub. Read some of our blogs to get a better feel for what we’re doing. Click sign in and create an account. Right now, you need a Google account to sign up but in the next few weeks we will support GitHub login and email/password. Sign up for our mailing list using the box on the right and we’ll tell you when. Choose a username. Check out some of our public datasets for inspiration. Star some of the ones you like.
Step 2: Create a New Repository on DoltHub to push to#
Now navigate to your repositories page which will be populated with the repos you starred. In the top right corner click the Create New Repository link. You will be greeted by the following page:
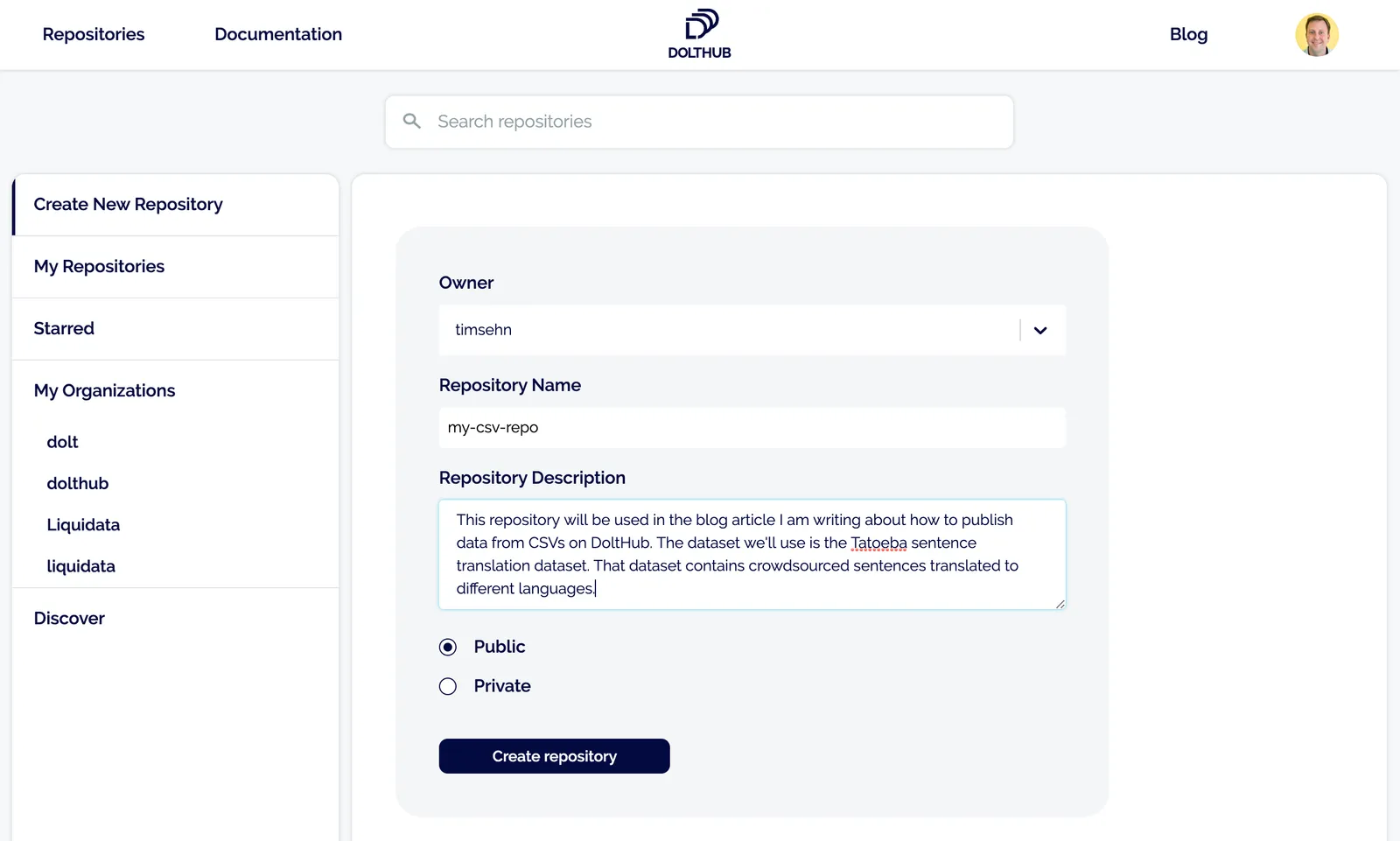
Leave the owner as is and pick a descriptive repository name. Add a description for others if you’d like. Leave the repository Public unless you want it to be private only to you. Private repositories on DoltHub are a paid feature.
After clicking create you’ll have a new empty repository on your repositories page that looks like this:
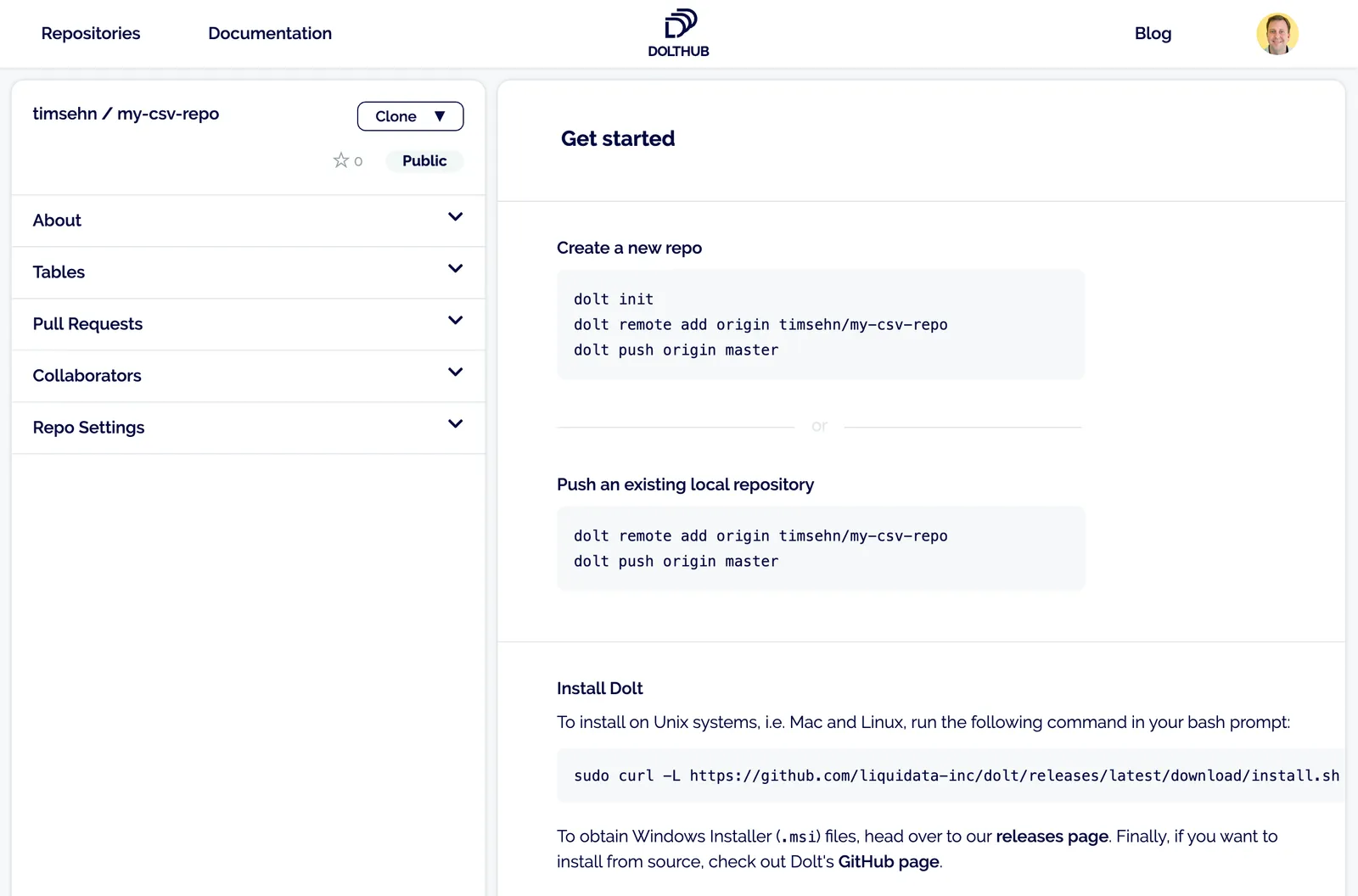
Now you have to populate the repository with some data.
Step 3: Install Dolt Locally#
Now you want to create a repository locally and get data into it.
First step is getting the Dolt command line application. Dolt looks a lot like Git all the way down to the help documentation. If you are familiar with Git, you can use your exact same flows but you are working with tables, not files.
Getting the command line depends on your operating system. For *nix and Mac systems, open up a terminal and run:
sudo curl -L https://github.com/dolthub/dolt/releases/latest/download/install.sh | sudo bashThis will download the latest release of Dolt and put it on your path. For Windows users, download and run the most current Microsoft installer (.msi file) from the Dolt release page on GitHub.
Now that it’s installed, run dolt in a terminal. You should see:
shell$ dolt
Valid commands for dolt are
init - Create an empty Dolt data repository.
status - Show the working tree status.
add - Add table changes to the list of staged table changes.
reset - Remove table changes from the list of staged table changes.
commit - Record changes to the repository.
sql - Run a SQL query against tables in repository.
sql-server - Starts a MySQL-compatible server.
log - Show commit logs.
diff - Diff a table.
blame - Show what revision and author last modified each row of a table.
merge - Merge a branch.
branch - Create, list, edit, delete branches.
checkout - Checkout a branch or overwrite a table from HEAD.
remote - Manage set of tracked repositories.
push - Push to a dolt remote.
pull - Fetch from a dolt remote data repository and merge.
fetch - Update the database from a remote data repository.
clone - Clone from a remote data repository.
creds - Commands for managing credentials.
login - Login to a dolt remote host.
version - Displays the current Dolt cli version.
config - Dolt configuration.
ls - List tables in the working set.
schema - Commands for showing and importing table schemas.
table - Commands for copying, renaming, deleting, and exporting tables.
conflicts - Commands for viewing and resolving merge conflicts.Looks like Git, right? That’s what we’re going for.
Step 4: Create a Dolt repository and link it to DoltHub#
Now that you have your local copy of Dolt, you need to make a repository and connect Dolt to DoltHub so you can push the repository there.
First, set your dolt username and email. Run the following commands:
$ dolt config --global --add user.email YOU@DOMAIN.COM
$ dolt config --global --add user.name "YOUR NAME"This lets Dolt know which user name and email to put on your commits as well as what account to link to when you run dolt login. Run dolt login now. Your terminal will wait and a browser window will open to the DoltHub credentials page:
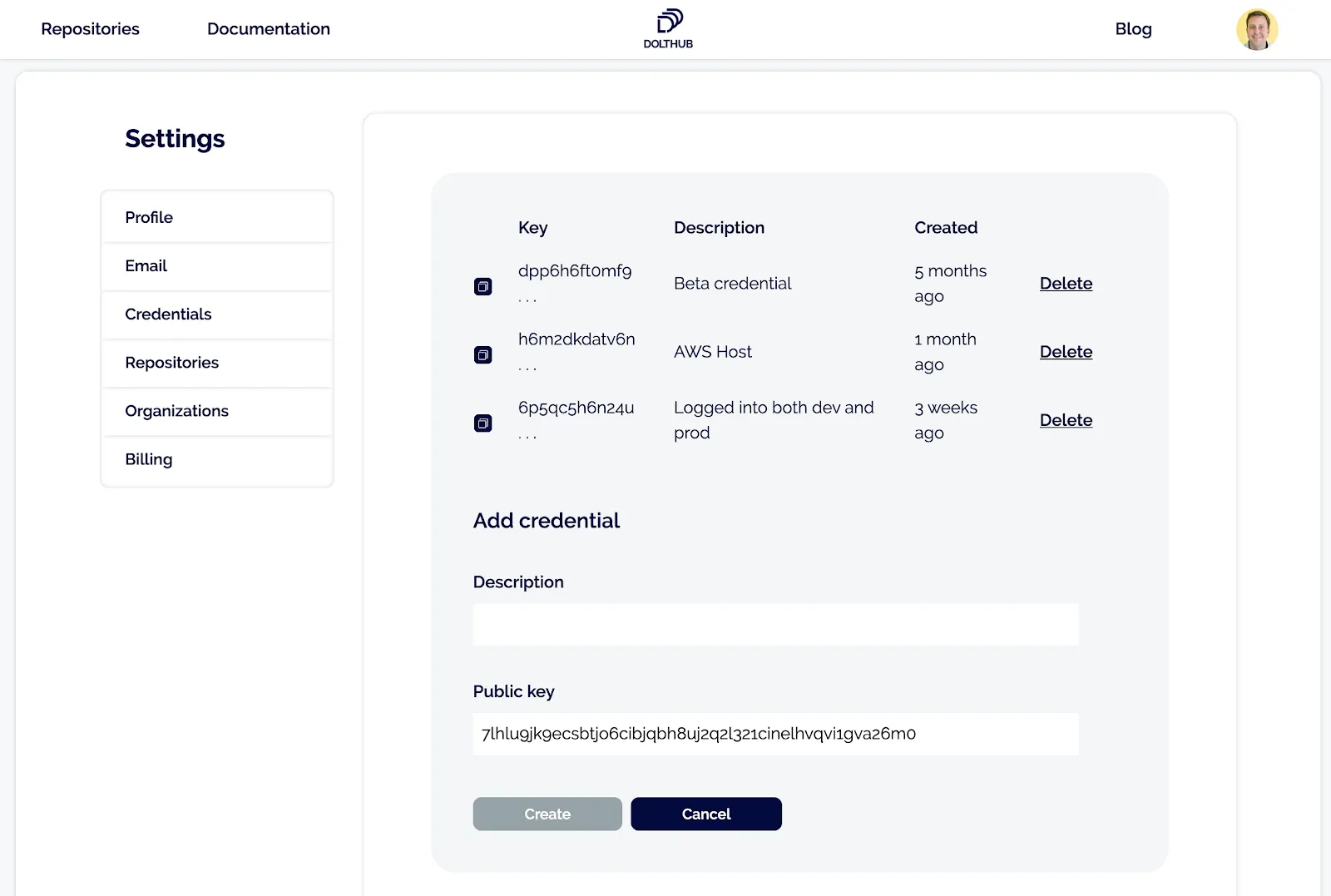
Add a description and click the Create button. Your terminal is polling DoltHub waiting for you to create the credential. Once you click Create, your terminal should return like so:
shell$ dolt login
Credentials created successfully.
pub key: 7lhlu9jk9ecsbtjo6cibjqbh8uj2q2l321cinelhvqvi1gva26m0
/Users/timsehn/.dolt/creds/8umkfb37c3l8q02au07fs447c6cjmg0kk1j4jm0ohn2rm.jwk
Opening a browser to:
https://dolthub.com/settings/credentials#7lhlu9jk9ecsbtjo6cibjqbh8uj2q2l321cinelhvqvi1gva26m0
Please associate your key with your account.
Checking remote server looking for key association.
requesting update
Key successfully associated with user: timsehn email tim@liquidata.coNow make a directory named after your repository, in this case, mkdir my-csv-repo. Then navigate to that directory and run dolt init to let dolt know this directory will contain a dolt repository. Tell the repository that it has a DoltHub remote by running dolt remote add origin timsehn/my-csv-repo.
dolt init creates a README.md and LICENSE.md file for you. You can edit the files if you’d like or delete them if you don’t want them. Dolt versions these files for you. You can add them to commits, diff them between versions, and all the rest of that good versioning stuff. They are displayed on DoltHub under the About section of your repository. Your README.md is the title page for your repository on DoltHub.
Once you are ready make a commit using dolt add and dolt commit. Then, you run dolt push origin master and your new repository will be available on DoltHub. It won’t have anything in it yet except your LICENSE.md and README.md file(s) but it will not be completely empty anymore.
This workflow should be familiar if you’ve used Git in the past. We’ve built Dolt and DoltHub with Git as the model.
Step 5 Prepare Your Data#
Get the data you want to import ready. Data with a natural primary key(s) works best. A primary key is an ID field or set of fields that will not have any duplicates in the table. Dolt uses primary keys to resolve differences and merges between versions so creating a Dolt table requires one or more primary keys that are not NULL (or blank).
Data that comes in CSVs is usually dumped from a database or an export of a spreadsheet. If it’s a database dump, it’s often structured with a primary key. These are usually called some form of ID. If the data comes from a spreadsheet, there is sometimes no natural primary key. In this case, you have a few options:
- Make every column a primary key. This will work but prevent duplicate rows.
- Manually assign an ID column as a primary key. This will be ok for this import. But if you import the data again, you need to assign IDs in the same way to get good diffs from Dolt.
- Make a hash of each column as the primary key and add a count column for duplicate rows. This is getting complicated but is the best solution. When we support tables without primary keys, Dolt will take this approach at the storage layer.
Sometimes data that comes in CSVs is “pivoted”. This means that two tables have been joined into one. In databases, it is common to have a table with individual details and a one to many table representing categories. Sometimes to dump this type of table into a single CSV the data is joined and you end up with a CSV that looks like ID, name, description, category1, category2, category3. It’s often useful to “unpivot” the data ie. put it back into the two table form it probably came from. In this case, you make one csv with ID, name, description and another with ID, categories. These become two relational tables with primary keys ID and ID, categories respectively.
Lastly, CSVs have a particularly hard time with NULLs. Many CSVs we run into use ‘n/a’ or ‘none’ to represent NULL. Often, we have to clean data with sed or some scripting language to get it ready for import.
The data we’re going to use in this example comes from the Tatoeba sentence translation database. The database contain 8.3M sentences across 355 languages with 17.3M translation relationships between sentences. It comes out once per week and we have been importing it into Dolt since September so it has a pretty rich version history. The Dolt version can be found here. The sample queries in the Query Catalog give a good idea how the data can be used.
The Tatoeba sentence translation dataset was chosen because it has a relatively simple schema across two tables. But, it’s complicated enough to be interesting. In preparation for this blog, I created this tarball with the two cleaned CSVs you will be importing. Download and unpack it now.
Step 6: Import your Data#
Dolt has a cool feature called schema import that will infer the database schema from a CSV. It’s not perfect but it often gets you 90%-100% of a working schema. You need to identify the primary key and then run dolt schema import with the table name and the CSV file to infer the schema from. I usually run a --dry-run first to make sure I’m getting a good schema. In this case, the primary key for sentences is SentenceID and the primary keys for translations are SentenceID and TranslationID. One sentence can have many translations.
dolt schema import --dry-run --create --pks SentenceID sentences sentences.csv
CREATE TABLE `sentences` (
`SentenceID` BIGINT NOT NULL COMMENT 'tag:0',
`Language` LONGTEXT COMMENT 'tag:1',
`Text` LONGTEXT NOT NULL COMMENT 'tag:2',
`Username` LONGTEXT COMMENT 'tag:3',
`DateAdded` LONGTEXT COMMENT 'tag:4',
`DateLastModified` LONGTEXT COMMENT 'tag:5',
PRIMARY KEY (`SentenceID`)
);Oh no! We don’t support DATETIME yet. That’s cool, I pipe the output to a file, sentences.schema, and replace the two DateAdded and DateLastModified LONGTEXT columns with DATETIME. Then I create the table using dolt sql < sentences.schema.
timsehn$ dolt schema import --dry-run --create --pks SentenceID,TranslationID translations translations.csv
CREATE TABLE `translations` (
`SentenceID` BIGINT NOT NULL COMMENT 'tag:0',
`TranslationID` BIGINT NOT NULL COMMENT 'tag:1',
PRIMARY KEY (`SentenceID`,`TranslationID`)
);That output looks good so we remove --dry-run and run the command to create the translations table.
Now That we have the schema, we must import the data. In Dolt, we use dolt table import for that. Note, dolt table import will also create a table for you but the schema will be all LONGTEXT types. Sometimes this is ok for quick and dirty imports but I prefer the two step schema import, table import workflow because it produces better schemas.
timsehn$ dolt table import -u sentences sentences.csv
Rows Processed: 8263868, Additions: 8263868, Modifications: 0, Had No Effect: 0
Import completed successfully.
timsehn$ dolt table import -u translations translations.csv
Rows Processed: 17348381, Additions: 17348381, Modifications: 0, Had No Effect: 0
Import completed successfully.It’s that simple. We now have a functioning database of sentence translations.
timsehn$ dolt sql -q "show tables"
+--------------+
| Table |
+--------------+
| sentences |
| translations |
+--------------+
timsehn$ dolt sql -q "describe sentences"
+------------------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------------+----------+------+-----+---------+-------+
| SentenceID | BIGINT | NO | PRI | | |
| Language | LONGTEXT | YES | | | |
| Text | LONGTEXT | NO | | | |
| Username | LONGTEXT | YES | | | |
| DateAdded | DATETIME | YES | | | |
| DateLastModified | DATETIME | YES | | | |
+------------------+----------+------+-----+---------+-------+Now it’s time to make some sample queries so the users of this database have some living documentation.
timsehn$ dolt sql -q "select * from sentences where Language='eng' and Text like '% dolt%'" --save "Find a sentence by word" --message "Basic query to find all sentences in a language with a particular word"
+------------+----------+------------------------+----------+-------------------------------+-------------------------------+
| SentenceID | Language | Text | Username | DateAdded | DateLastModified |
+------------+----------+------------------------+----------+-------------------------------+-------------------------------+
| 2040224 | eng | Stop being such dolts. | halfb1t | 2012-11-27 06:01:24 +0000 UTC | 2012-11-27 06:01:24 +0000 UTC |
+------------+----------+------------------------+----------+-------------------------------+-------------------------------+
timsehn$ dolt sql -q "select distinct sentences.sentenceID, sentences.Language, sentences.Text, sentences.Username, sentences.DateAdded, sentences.DateLastModified, translations.translationID from sentences join translations on translations.TranslationID=sentences.SentenceID where translations.SentenceID=2040224 or sentences.SentenceID=2040224" --save "Translations for a Sentence" --message "This query prints the sentence and all of its translations. Warning it takes about 10 minutes to complete on my MacBook Pro"
+------------+----------+-------------------------------+--------------+-------------------------------+-------------------------------+---------------+
| SentenceID | Language | Text | Username | DateAdded | DateLastModified | TranslationID |
+------------+----------+-------------------------------+--------------+-------------------------------+-------------------------------+---------------+
| 2040224 | eng | Stop being such dolts. | halfb1t | 2012-11-27 06:01:24 +0000 UTC | 2012-11-27 06:01:24 +0000 UTC | 2040224 |
| 1654755 | fra | Arrêtez d'être aussi idiots ! | sacredceltic | 2012-06-30 07:49:26 +0000 UTC | 2012-06-30 07:49:26 +0000 UTC | 1654755 |
| 2040242 | tur | Bu kadar aptal olmayı bırak. | duran | 2012-11-27 06:15:36 +0000 UTC | 2012-11-27 06:15:36 +0000 UTC | 2040242 |
| 2041113 | heb | אל תהיו כאלה טמבלים. | MrShoval | 2012-11-27 14:59:57 +0000 UTC | 2012-11-27 15:00:20 +0000 UTC | 2041113 |
+------------+----------+-------------------------------+--------------+-------------------------------+-------------------------------+---------------+
As an aside, for those wondering why that join takes 10 minutes, look at the explain output.
timsehn$ dolt sql -q "explain select distinct sentences.sentenceID, sentences.Language, sentences.Text, sentences.Username, sentences.DateAdded, sentences.DateLastModified, translations.translationID from sentences join translations on translations.TranslationID=sentences.SentenceID where translations.SentenceID=2040224 or sentences.SentenceID=2040224"
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| plan |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Distinct |
| └─ Project(sentences.SentenceID, sentences.Language, sentences.Text, sentences.Username, convert(sentences.DateAdded, datetime) as DateAdded, convert(sentences.DateLastModified, datetime) as DateLastModified, translations.TranslationID) |
| └─ Filter(translations.SentenceID = 2040224 OR sentences.SentenceID = 2040224) |
| └─ IndexedJoin(translations.TranslationID = sentences.SentenceID) |
| ├─ translations |
| └─ sentences |
+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+That filter (ie. where clause) should be pushed down below the indexed join. Our SQL engine doesn’t do the right thing here yet. It errs on the side of correctness, rather than performance. We’re working on it and you are welcome to as well. Dolt is open source.
Step 7: Publish to DoltHub#
Publishing to DoltHub is as simple as running dolt push origin master again. Now you can see your repository under https://www.dolthub.com/repositories/<user name>/<repository name>. The one I created is here.
Step 8: Tell your friends#
Share the link to your repository with anyone you know who might be interested. She can get a local copy of your repository by running dolt clone <user name>/<repository name>.
If she wants to make a change, she can use a standard Git workflow: dolt checkout -b <branch name>, make the change using SQL, dolt add <table name>, and dolt commit. Give them write permissions under the collaborators section and they can push their branch to DoltHub and create a Pull Request for you to review.
Conclusion#
Dolt makes transforming data from CSVs into a functioning SQL database as easy as possible. DoltHub is a great place to share databases for the world to collaborate on. Hopefully this example gives you enough experience to start uploading your own data.