Dolt and DoltHub: Getting Started

Dolt is a SQL database with Git-style versioning. In Git the unit of versioning is files. In Dolt, the unit of versioning is SQL tables. Dolt will eventually support 100% of the Git command line and 100% of MySQL SQL. Moreover, anything you can do on the Git command line, you will be able to do via SQL. Right now, we're at about 90% coverage of the Git command line and SQL.
DoltHub is a place to share Dolt repositories. In the Git context, you clone, push, and pull from DoltHub as if it was a remote. Like GitHub, DoltHub is a central place to collaborate on Dolt data projects. You can create or find public data to work on. You can give read and write permissions to your Dolt repositories to other users. You can have them create pull requests to improve your data. In the future we imagine DoltHub issues and releases. We also expect to invent some new data-specific features.
Sound interesting? We think so. This blog post is a guide to getting started.
Step 1: Take a DoltHub tour
Go to DoltHub. Read some of our blogs to get a better feel for what we're doing. Click sign in and create an account. Right now, you need a Google account to sign up but eventually we will support GitHub login and email/password. Choose a username. Check out some of our public datasets. Star some of the ones you like.
You have two options at this point: start your own data project or clone a public one you are interested in. We'll start with cloning a public one.
Step 2: Decide which dataset to clone
Baseball is the most data-friendly of all the sports. We're going to attempt a simple correlation analysis of home runs to player salary.
Go to the baseball-databank repository. On the left, you have the schema of the database and the Dolt metadata, like the commit log. On the right, you have a sample of the data in the database. This layout may change but those are the three sets of information this page displays. Soon, this page will have LICENSEs and READMEs. Eventually, it will have Issues and releases. The goal of this page is to give you all the information you need to decide whether this data is useful to you. What is in this database? When was it last updated? Who maintains it? How is it licensed? Is there any documentation?
What is in the database? You can run simple SQL queries against the data on DoltHub. What is the last season of batting statistics in this database?
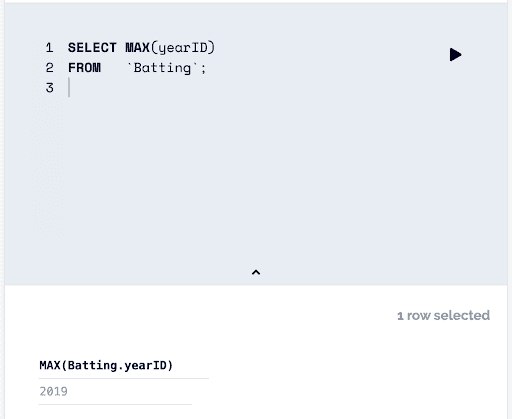
What about salary data? What data exists in that table? I want to do a correlation analysis between salary and batting prowess. Using the same interface, salary data in this dataset is updated to 2016. Still worth grabbing this data? I think so.
Let's stop and admire how easy Dolt and DoltHub made deciding whether this data is useful to you. The alternative is reading a web page, downloading a zip file of CSV files, realizing they are too big for spreadsheets, maybe doing some greps, and finally importing those into your database of choice to realize whether the data is good enough. Most people give up before they reach that point. With Dolt and DoltHub, figuring out if the data is for you is easy.
Step 3: Install Dolt locally
Now you want to do the correlation analysis of batting to player salary so you need the repository locally.
First step is getting the Dolt command line application. Dolt looks a lot like Git all the way down to the help documentation. If you are familiar with Git, you can use your exact same flows but you are working with tables, not files.
Getting the command line depends on your operating system. For *nix and Mac systems, open up a terminal and run:
sudo curl -L https://github.com/dolthub/dolt/releases/latest/download/install.sh | sudo bashThis will download the latest release of Dolt and put it on your path. For Windows users, download and run the most current Microsoft installer (.msi file) from the Dolt release page on GitHub.
Now that it's installed, run dolt in a terminal. You should see:
shell$ dolt
Valid commands for dolt are
init - Create an empty Dolt data repository.
status - Show the working tree status.
add - Add table changes to the list of staged table changes.
reset - Remove table changes from the list of staged table changes.
commit - Record changes to the repository.
sql - Run a SQL query against tables in repository.
sql-server - Starts a MySQL-compatible server.
log - Show commit logs.
diff - Diff a table.
blame - Show what revision and author last modified each row of a table.
merge - Merge a branch.
branch - Create, list, edit, delete branches.
checkout - Checkout a branch or overwrite a table from HEAD.
remote - Manage set of tracked repositories.
push - Push to a dolt remote.
pull - Fetch from a dolt remote data repository and merge.
fetch - Update the database from a remote data repository.
clone - Clone from a remote data repository.
creds - Commands for managing credentials.
login - Login to a dolt remote host.
version - Displays the current Dolt cli version.
config - Dolt configuration.
ls - List tables in the working set.
schema - Commands for showing and importing table schemas.
table - Commands for copying, renaming, deleting, and exporting tables.
conflicts - Commands for viewing and resolving merge conflicts.Looks like Git right? That's what we're going for.
Step 4: Clone the repository
Now that you have your local copy of Dolt, you need to connect Dolt to DoltHub so you can get the data you need locally.
First, set your dolt username and email. Run the following commands:
$ dolt config --global --add user.email YOU@DOMAIN.COM
$ dolt config --global --add user.name "YOUR NAME"This lets Dolt know which user name and email to put on your commits as well as what account to link to when you run dolt login. Run dolt login now. Your terminal will wait and a browser window will open to the DoltHub credentials page:
Add a description and click the Create button. Your terminal is polling DoltHub waiting for you to create the credential. Once you click Create, your terminal should return like so:
shell$ dolt login
Credentials created successfully.
pub key: 7lhlu9jk9ecsbtjo6cibjqbh8uj2q2l321cinelhvqvi1gva26m0
/Users/timsehn/.dolt/creds/8umkfb37c3l8q02au07fs447c6cjmg0kk1j4jm0ohn2rm.jwk
Opening a browser to:
https://dolthub.com/settings/credentials#7lhlu9jk9ecsbtjo6cibjqbh8uj2q2l321cinelhvqvi1gva26m0
Please associate your key with your account.
Checking remote server looking for key association.
requesting update
Key successfully associated with user: timsehn email tim@liquidata.coNow, you're ready to clone the baseball-databank repository. Navigate to a directory where you want your data to live and run:
dolt clone dolthub/baseball-databankThis will create a baseball-databank directory. Change your working directory to baseball-databank and run dolt ls.
shell$ dolt ls
Tables in working set:
AllstarFull
Appearances
AwardsManagers
AwardsPlayers
AwardsShareManagers
AwardsSharePlayers
Batting
BattingPost
CollegePlaying
Fielding
FieldingOF
FieldingOFsplit
FieldingPost
HallOfFame
HomeGames
Managers
ManagersHalf
Parks
People
Pitching
PitchingPost
Salaries
Schools
SeriesPost
Teams
TeamsFranchises
TeamsHalfYou have a copy of all the data and all of its history locally now. Run dolt log to see what's changed or dolt checkout -b new-branch to checkout a new branch. You can use all your familiar Git workflows in the exact same way with Dolt.
Moreover, you have a full SQL query interface to the data. Let's explore that next.
Step 5: Get the data you need using SQL
I have a general idea of what I need. I need Player salaries and Home Runs per year. Looking at the tables above I think I need to look at Batting and Salaries.
shell$ dolt sql -q "describe Salaries"
+----------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+----------+------+-----+---------+-------+
| yearID | BIGINT | NO | PRI | | |
| teamID | LONGTEXT | NO | PRI | | |
| lgID | LONGTEXT | NO | PRI | | |
| playerID | LONGTEXT | NO | PRI | | |
| salary | BIGINT | NO | | | |
+----------+----------+------+-----+---------+-------+
shell$ dolt sql -q "describe Batting"
+----------+----------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+----------+----------+------+-----+---------+-------+
| playerID | LONGTEXT | NO | PRI | | |
| yearID | BIGINT | NO | PRI | | |
| teamID | LONGTEXT | NO | PRI | | |
| lgID | LONGTEXT | NO | PRI | | |
| stint | BIGINT | NO | | | |
| G | BIGINT | NO | | | |
| AB | BIGINT | NO | | | |
| R | BIGINT | NO | | | |
| H | BIGINT | NO | | | |
| 2B | BIGINT | NO | | | |
| 3B | BIGINT | NO | | | |
| HR | BIGINT | NO | | | |
| RBI | BIGINT | YES | | | |
| SB | BIGINT | YES | | | |
| CS | BIGINT | YES | | | |
| BB | BIGINT | NO | | | |
| SO | BIGINT | YES | | | |
| IBB | BIGINT | YES | | | |
| HBP | BIGINT | YES | | | |
| SH | BIGINT | YES | | | |
| SF | BIGINT | YES | | | |
| GIDP | BIGINT | YES | | | |
+----------+----------+------+-----+---------+-------+I would consider myself a C- in SQL skills but after a bit of Googling I was able to cobble together this query:
SELECT Salaries.yearID, Salaries.playerID, Salaries.salary, Batting.HR FROM Salaries
INNER JOIN Batting on Salaries.YearID=Batting.YearID AND Salaries.PlayerID=Batting.PlayerID AND Salaries.teamID=Batting.teamID AND Salaries.lgID=Batting.lgID
WHERE Batting.AB>50I first ran the query without the AB>50 (ie. at bats > 50) clause but that gave me a lot of pitchers with 0 home runs so I think adding a filter for greater than 50 at bats is useful. Using SQL for data discovery and testing is quick, interactive, and requires no code.
I then ran this query with dolt sql -r csv -q "<QUERY>" > salary-hr.csvto get the results in a format I could use for analysis.
Step 6: Analyze the data
I used Google Sheets to analyze the data. I wanted to create a linear regression of each year of salary to home runs and see if the R-squared changed over time. How predictive is player salary of home runs in any given year? Was there a time where the highest paid players were more likely to be home run hitters?
You can check out my work here. I imported the CSV file to start. Then, I made a scatter plot for each year with the linear trend line and the R-squared. The goal of Dolt is to make getting data into the tools you use for analysis and visualization easy.
It looks like the steroids era in baseball, 1994-2004, corresponded with an era where R-squared between salary and home runs was most correlated. The R-squared is still not very predictive, 0.18-0.27, but around double what it is for the rest of the seasons in the dataset, 0.08-0.10.
There's a lot more you can explore here if you have an inclination to play. What if you add a lag between the year of the home run total and salary to simulate paying for past performance? What if you filter out minimum salary players and players with less than 100 at bats?
Step 7: Try Dolt and DoltHub yourself
You should have everything you need now to try Dolt and DoltHub for yourself. Go explore some public datasets and create some analyses of your own. Let us know if there is any data you want us to gather and upload. We're going to spend the next few months building up our data catalog with interesting, maintained datasets. So, check DoltHub often to see what is new.