
When you build a database from scratch, you hear a lot of reasons why potential customers choose not to use it. Dolt adds compelling Git-like version control features to the classic SQL database. These features are enough to get a lot of people excited. Branch, merge, diff, push, and pull on my SQL database. Imagine what I could build!
This blog collects all the common reasons we’ve heard over the years that people shy away from Dolt. After each reason, we offer a set of our standard rebuttals. We hope this convinces you to give Dolt a try.

Reason #1: Dolt is not Postgres-compatible#
Dolt is MySQL-compatible. When we were building Dolt in 2018, Postgres had not reached its current hegemon in the open source database world. MySQL was still really popular. Plus, an open source pure Golang implementation of a MySQL server existed. We made Dolt MySQL-compatible and have kept getting more compatible ever since. At this point, we’re so compatible that if you find one, we’ll fix a MySQL compatibility bug in 24 hours or less.
All that said, given Postgres’ supremacy in the database world, a common reason people do not adopt Dolt is “it’s not Postgres”.
Yeah But: Doltgres is in early Alpha
We heard this for so long that we finally caved and started on a Postgres-flavored Dolt called Doltgres. The initial version was released in November 2023.

The current version is still early Alpha with sequences and schema support recently added. We expect a Beta version that would be ready for experimental adoption in Q4 2024 or Q1 2025. The best way to use Doltgres right now is as a replica of a running Postgres primary.
Yeah But: Dolt contains no MySQL code
Even so, it’s not like Dolt is a product of big Oracle. Dolt contains no MySQL code. To provide version control features at scale, Dolt is built from the ground up using a custom storage engine based on a novel data structure called a Prolly Tree. Frankly, the SQL flavor is the least interesting thing about Dolt.
Reason #2: Database + History Doesn’t Scale#
We hear some version of “I can barely fit all my current data in my database. I can’t possibly store all the history of my database as well.” We get it. As software engineers, we’ve been taught to think about scale. What happens when my database gets really big? What are my options to make it even bigger?
Dolt is architected like MySQL or Postgres. It is meant to be run on a single primary server with multiple replicas for read scaling. If you need a primary bigger than a single server, you must shard the data at the application layer.
Yeah But: Dolt Structurally Shares Storage
Let’s first address the history question. Dolt chunks up your database into approximately 4 kilobyte pieces. These chunks are content-addressed. This content-addressing allows for any repeated chunks to only be stored once. This is called structural sharing and it is a key property of version control systems. Version control systems don’t scale if you store a whole copy of every version.
For example, in Dolt, if you only change one row of a one million row table one thousand times, the other 999,999 rows are stored once. The total size of your database plus history is 1,001,000 rows. This assumes that row is in a single chunk as a simplification. This means your database grows with the size of its history but not in a doubling on every write kind of way.
Dolt scales on disk pretty well for most common use cases. Hard drives are very big now. Dolt has databases in production that are about 1TB, including history.
Yeah But: We’re building an archive format to save 50% disk space
That said, we know people worry about deep commit histories overwhelming the disk on any single host. We’re hard at work on a compression format that saves approximately 50% of disk space for database history. We’re still working out the kinks with read performance. At least, this format will be accessed via a command like dolt gc --archive. At most, this will be the default format for chunks in history shrinking all Dolt databases by 50%.
Yeah But: Dolt will soon allow history offloading to a remote
Once the archive format work is complete, we will allow you to offload history to a remote copy of your database. This will be based on the work already done to enable shallow clone. Shallow clone allows you to only clone the HEAD version of a Dolt database plus a configurable number of previous revisions. History offloading works as a kind of inverse shallow clone. Dolt will push all chunks to a remote and then delete a configurable amount of history on garbage collection, leaving a shallow clone behind. Dolt will pull the history it needs locally if you query it.
Reason #3: Dolt is Too Slow#
Surely, all that version control overhead slows Dolt down? There’s no way Dolt has credible OLTP database performance.
Yeah But: When was the last time you checked Dolt query performance
Dolt may have been slow in the past but after years of optimization Dolt stands at approximately 1.7X slower than MySQL on a standard suite of sysbench tests and 3X slower on a much more concurrent TPC-C benchmark. Dolt is slower than MySQL but not that much slower.
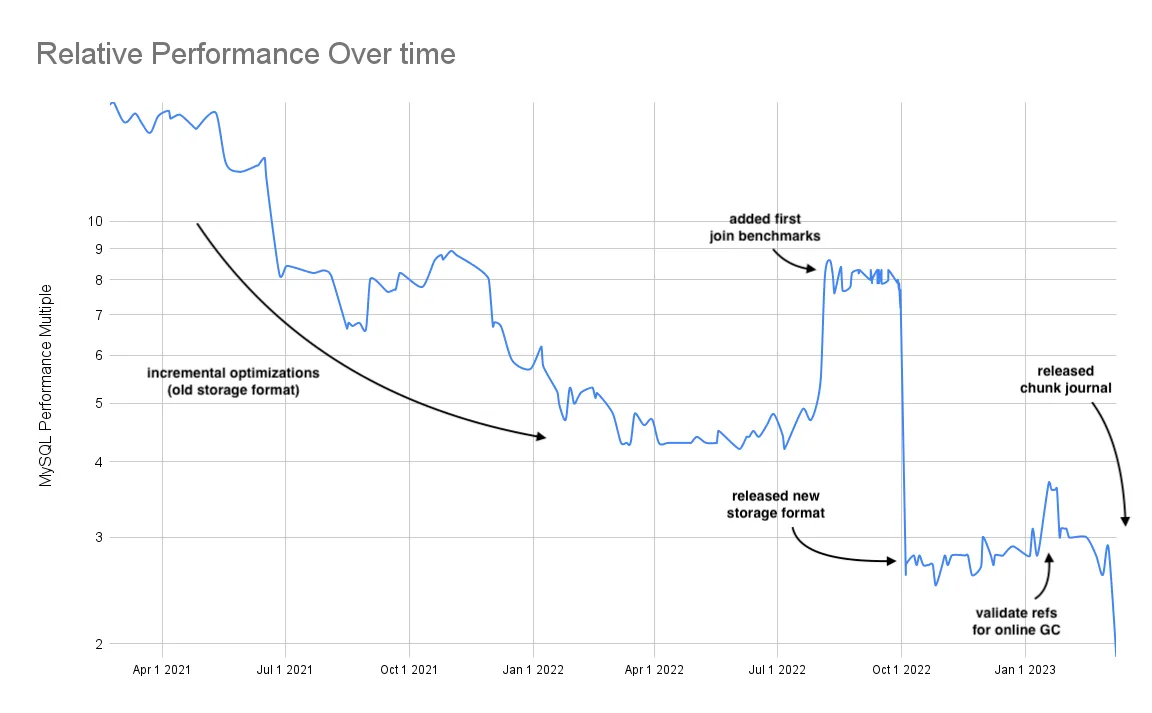
Yeah But: Dolt is about equal on write speed to MySQL
On a standard suite of sysbench write tests, Dolt performs at approximate parity with MySQL, outperforming MySQL on pure write latency tests.
Yeah But: Dolt is about 2X slower on read speed to MySQL
On a suite of standard sysbench read tests, Dolt performs approximately 2X slower than MySQL. We are actively optimizing this number right now with the goal of breaking the 2X barrier in the coming months.
Yeah But: Most of our customers don’t even notice
One has to remember that database latencies are a small component of your overall application performance. Database latencies are generally measured in microseconds whereas application latencies are measured in milliseconds. Most of our customers can’t even see the difference in Dolt performance at the application layer.
Yeah But: Run Dolt as a replica of your MySQL and get most of the features
If you’re still concerned about latency after reading the above, you can always run Dolt as a read replica of a MySQL primary and get most of the version control features there. You’ll get MySQL performance on your primary and Dolt’s version control features on a replica for history inspection, disaster recovery, and developer productivity. The only Dolt feature you lose on your primary is merges but you can merge using a patch procedure.
Yeah But: You’ll soon be able to replicate a branch to MySQL for read performance
Dolt will soon produce a MySQL-compatible binlog. When that ships, you’ll be able to set up a read-only MySQL replica of a Dolt branch. This MySQL replica can be used for low latency reads.
Reason #4: Dolt is Too New#
Dolt’s main competitors are MySQL and Postgres, which are 30 and 40 years old respectively. Dolt is brand new, released in August 2019 and going 1.0 in May 2023. Many potential Dolt users are worried that Dolt is not mature enough to store their critical data.
Yeah But: Dolt is about 10 years old
If you count Noms, Dolt’s predecessor and first entry in Dolt’s commit log, Dolt is over 9 years old.
$ pwd
/Users/timsehn/dolthub/git/dolt
$ git log --reverse | head -6
commit 68c3ac02058e559367534aeeb7d9f8f483a4db1b
Author: Aaron Boodman <aaron@aaronboodman.com>
Date: Tue Jun 2 20:45:33 2015 -0700
first commit
There was code produced before this commit that was moved into this Git repository. The idea of a version controlled database based on a content-addressed B-tree stored in a commit graph is almost ten years old.
Dolt itself is almost 6 years old in November 2024. Brian put the Git command line on Noms and we had our first product. Dolt has the cumulative battle scars to shrug off the “too new” label.
Yeah But: Dolt is 1.0

Dolt went 1.0 in May 2023. Dolt was fast enough, compatible enough, and stable enough to announce it was ready for production workloads. A year past Dolt is even better.
Yeah But: Dolt is Trusted in Production
Many customers trust Dolt in production. Turbine has used Dolt in production for over three years now. Flock Safety uses Dolt as their feature store for machine learning. Scorewarrior uses Dolt to master their game configuration. FJA and Threekit uses Dolt to provide branch and merge in their applications.
We also use Dolt in production ourselves. The DoltHub website itself uses Dolt to store its metadata. Dolt has been carrying the DoltHub workload with very few issues for over a year now.
Conclusion#
Customers have valid concerns about adopting Dolt for their use case. We’re constantly working to invalidate these concerns. Dolt is ready for your production use cases. Have a different concern not addressed here? Come by our Discord and hear our “Yeah, buts” for that one.